Scraping Indeed job postings
So, what is the easiest way to get all the job posting details from Indeed.com?
Option 1: Subscribe to Specrom’s job posting data feed
We have an Job feed that will extract all the pertinent job posting information such as company name, city, snippet, job title etc. by just specifying a search query and a location.
The API is available on RapidAPI and there is a free trial with no credit card information required. Paid plans start at just $10.
Option 2: Full service web scraping service.
If you just need job postings data as a CSV or excel file, then simply contact us for our full service web scraping service. You can simply sit back and let us handle all the backend issues to get the data you need.
Option 3: Scrape indeed.com on your own
Python is great for web scraping and we will be using a library called Selenium to extract Job postings from Indeed for Atlanta, GA.
Fetching raw html page from the Indeed
We will automate entering of search query and location into the textbox and clicking enter using Selenium
### Using Selenium to extract Indeed.com's raw html source
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
import time
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
test_url = 'https://www.indeed.com/'
option = webdriver.ChromeOptions()
option.add_argument("--incognito")
chromedriver = r'chromedriver.exe'
browser = webdriver.Chrome(chromedriver, options=option)
browser.get(test_url)
text_area = browser.find_element_by_id('text-input-what')
text_area.send_keys("Web scraping")
text_area2=browser.find_element_by_id('text-input-where')
text_area.send_keys("Atlanta, GA")
element = browser.find_element_by_xpath('//*[@id="whatWhereFormId"]/div[3]/button')
element.click()
html_source = browser.page_source
browser.close()
Using BeautifulSoup to extract Indeed job postings
Once we have the raw html source, we should use a Python library called BeautifulSoup for parsing the raw html files.
- You should open the page in the chrome browser and click inspect.
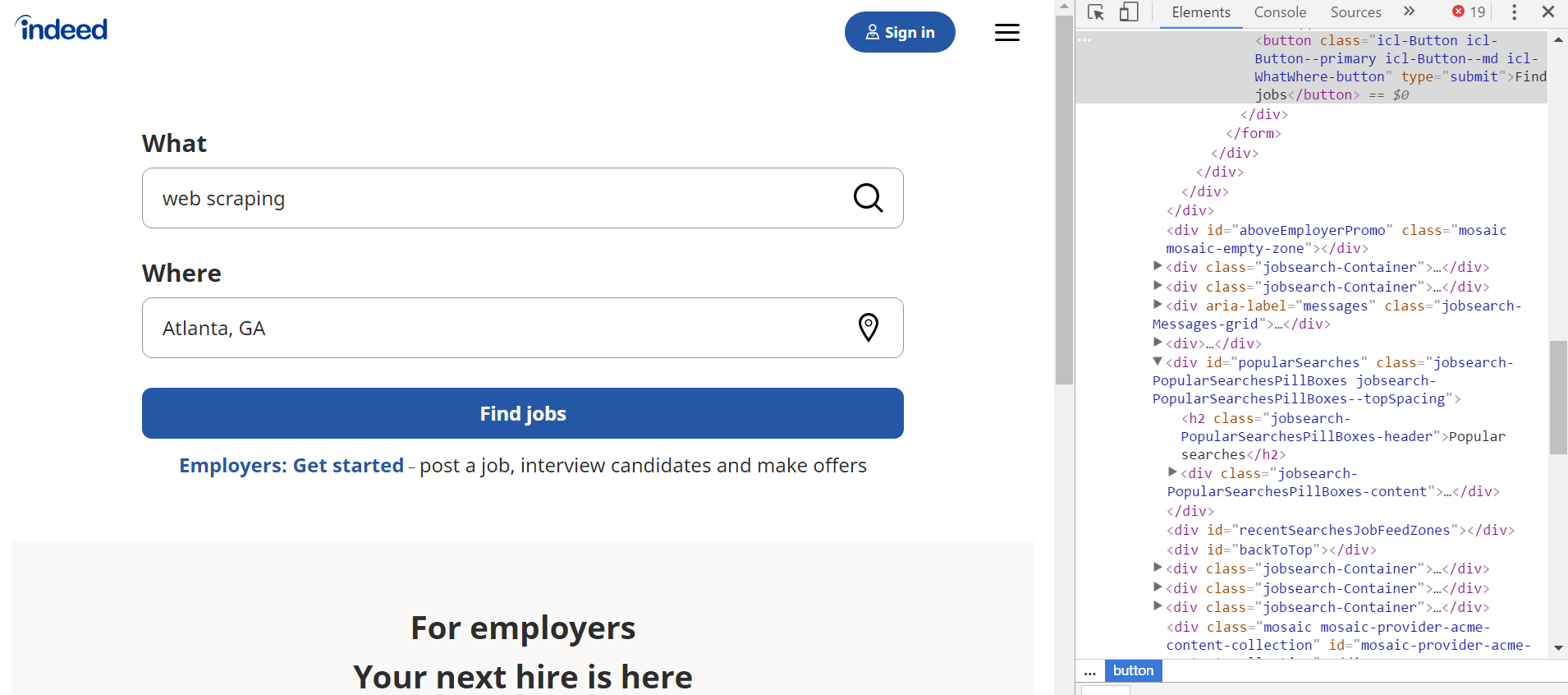
Figure 1: Inspecting the source of HTML source code for Indeed.com search query webpage.
Extracting job titles
From inspecting the html source, we see that job titles have h2 tags and belong to class ‘title’.
# extracting job titles
soup=BeautifulSoup(html_source, "html.parser")
job_title_src = soup.find_all('h2', {'class','title'})
job_title_list = []
for val in job_title_src:
try:
job_title_list.append(val.get_text())
except:
pass
job_title_list
#Output
['Data Analyst',
'Data Analyst',
'Data/Reporting Analyst',
'Sr. Data Analyst',
'Data Analyst',
'Data Analyst',
'Behavior Data Analyst - Marcus Autism Center - Behavioral Analysis Core',
'Data Analyst',
'Data Analyst',
'Police Analyst',
'Data Analyst (2021-1614)',
'Employee Data Analyst',
'Data Analyst',
'Data and Research Analyst',
'Data Analyst (13255)']
Extracting company names
The next step is extracting company names. We see that it is span tag of class ‘company’.
# extracting Indeed addresses
company_name_src = soup.find_all('span',{'class', 'company'})
company_name_list = []
for val in company_name_src:
company_name_list.append(val.get_text())
company_name_list
# Output
['KIPP Foundation',
'Emory University',
'City of Atlanta, GA',
'The Coca-Cola Company',
'KIPP Metro Atlanta Schools',
'Spartan Technologies',
"Children's Healthcare of Atlanta",
'ARK Solutions',
'Anthem',
'City of Forest Park, GA',
'Atrium CWS',
'Salesforce',
'Sovos Compliance',
'Southern Poverty Law Center',
'Baer Group']
Extracting snippets
Snippets are couple of sentences of text that briefly explain the job postings. Along with job title and company name, these are one of the most important pieces of information to extract from each Indeed job posting result.
As a reference, refer to the figure below.
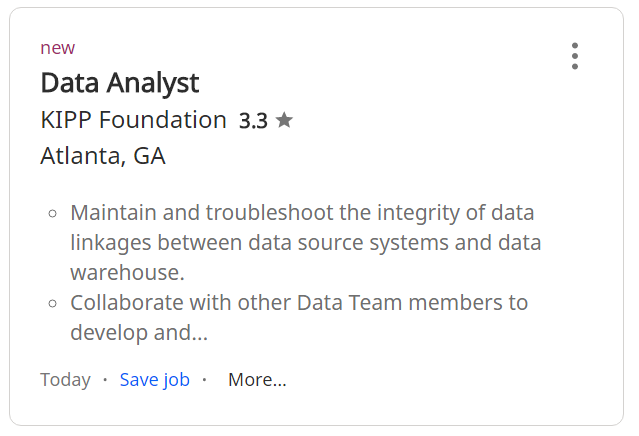
Figure 2: individual job postings from Indeed.com search results.
- We will extract snippet for each job postings. For brevity we will only show results from first three job postings, and you can verify that the first result matches the text in figure 2 above.
# extracting snippets from each job postings
snippet_src = soup.find_all('div', {'class', 'summary'})
snippet_list = []
for val in snippet_src:
snippet_list.append(val.get_text())
snippet_list[:3]
# Output
['\n\nMaintain and troubleshoot the integrity of data linkages between data source systems and data warehouse.\nCollaborate with other Data Team members to develop and…\n',
'\n\nCreates and maintains a data dictionary and meta data.\nAnalyzing data reporting data for clinical outcomes, qualitative and other types of research.\n',
'\n\n3 years of work experience in creation, reporting, and/or management of data or closely related tasks (not including data entry).\n']
Converting into CSV file
You can take the lists above, and read it as a pandas DataFrame. Once you have the Dataframe, you can convert to CSV, Excel or JSON easily without any issues.
Scaling up to a full crawler for extracting all Indeed job postings
Once you scale up to make thousands of requests to fetch all the pages, the indeed.com servers will start blocking your IP address outright or you will be flagged and will start getting CAPTCHA.
To make it more likely to successfully fetch data for all USA, you will have to implement:
- rotating proxy IP addresses preferably using residential proxies.
- rotate user agents
- Use an external CAPTCHA solving service like 2captcha or anticaptcha.com
After you follow all the steps above, you will realize that our pricing for managed web scraping or our Indeed scraper API is one of the most competitive in the market.