Scraping News Articles from CNN using Python
Try our Twitter Scraper Now! Web scraping is the extraction of structured information from webpages. Major news outlets like CNN and CNNMoney are excellent sources for getting objective financial and stock market-related information.
You will have to select which portions of the page you want to extract. Typically, people want to extract author names, dates, titles, and full text of the news article.
If you Google “web scraping CNN” than you will probably come across numerous articles and blogs outlining common methods to do it in Python. Let us go through the top methods below.
Easy Method: Specrom Latest News API
We can get the latest news from CNN is by using our Latest News API. Its completely free to use in basic tier forever and premium packages start from $10/month in contrast with hundreds of dollars a month with our competitors.
You can search the latest news by queries appearing in the full text of the article or by just the title in addition to searching by major topics (politics, business, etc.) a full list of all the features are available on its documentation page.
Example client codes are available on the above link for all major programming languages such as Java, Python, etc. so it’s perfect for painless integration into your application.
Input:
{"domains": "cnn.com","topic":"politics","q": "","qInTitle": "", "content":"false", "page":"1", "author_only":"true"}
Output:
{
"Article": [
{
"author": "[\"Lauren Fox and Ted Barrett, CNN\"]",
"description": "Divisions within the Republican conference spilled out once again Tuesday as GOP senators dismissed key pieces of their own leadership's stimulus proposal not even a day after its release.",
"publishedAt": "2020-07-28",
"source_name": "CNN",
"source_url": "cnn.com",
"title": "Republicans revolt against GOP's initial stimulus plan - CNNPolitics",
"url": "https://www.cnn.com/2020/07/28/politics/republican-reaction-gop-stimulus-plan/index.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+rss%2Fcnn_allpolitics+%28RSS%3A+CNN+-+Politics%29",
"urlToImage": "https://cdn.cnn.com/cnnnext/dam/assets/200518181852-senator-ben-sasse-1-super-tease.jpg"
},
.
.
.
],
"status": "ok",
"totalResults": 113
}
It is incredibly easy to get hundreds of latest news articles for all major news domains by simply calling this API.
Easy Method: News Extraction API
If you already have an article you want to scrape than simply use an API that can extract all the details of the news article such as full-text content, feature image URL, author, date, etc. There are numerous such free to use APIs out there but I recommend that you use the News Extraction API.
Example client codes are available on the above link for all major programming languages such as Java, Python, etc. so it’s perfect for painless integration into your application.
Its usage is pretty simple, all you need is specifying an URL and get back the results in a structured format.

News Extraction API
Python and BeautifulSoup
BeautifulSoup is a popular HTML parsing library and it’s probably first on the list for most people for parsing content from web parsing. Let us extract news title, author, publishing date, and full text using Beautifulsoup and requests library which fetches the raw HTML from the web. We will scrape a recent news article on Facebook.
from bs4 import BeautifulSoup
html_response = r.text
soup = BeautifulSoup(html_response,'html.parser')
print("Title: ", soup.find('h1').get_text())
temp_ls = soup.find_all('span', {"class":'metadata__byline__author'})
for temp in temp_ls:
print("Author: ", temp.find('a').get_text())
temp_time = soup.find('p', {'class':'update-time'})
print("Time: ", temp_time.get_text())
def get_full_text(doc):
soup = BeautifulSoup(doc, 'html.parser')
for s in soup(['script', 'style']):
s.extract()
return (soup.text.strip()).encode('ascii', 'ignore').decode("utf-8")
print("Fulltext:", get_full_text(html_response)
Output:
Title: Here's how big Facebook's ad business really is
Author: Rishi Iyengar
Time: Updated 1319 GMT (2119 HKT) July 1, 2020
FullText: 'Here\'s how big Facebook\'s ad business really is - CNN\n\n\n\nMarketsTechMediaSuccessPerspectivesVideosEditionU.S.InternationalArabicEspaolSearch CNNOpen MenuMarketsTechMediaSuccessPerspectivesVideosSearchEditionU.S.InternationalArabicEspaolMarketsPremarketsDow 30After-HoursMarket MoversFear & GermanyMoreAccessibility & CCAbout UsNewslettersWorldUS PoliticsBusinessHealthEntertainmentTechStyleTravelSportsVideosFeaturesMoreWeatherFollow CNN Business\n\nHere\'s how big Facebook\'s ad business really isBy Rishi Iyengar, CNN BusinessUpdated 1319 GMT (2119 HKT) July 1, 2020 Chat with us in Facebook Messenger. Find out what\'s happening in the world as it unfolds.JUST WATCHEDHear both sides of the debate over free speech on social mediaReplayMore Videos ...MUST WATCH (15 Videos)Hear both sides of the debate over free speech on social mediaTwitter labels video Trump tweeted as \'manipulated media\
The good news is that it extracts almost all the information you needed, however, it takes considerable prior experience with scraping from CNN in locating the right HTML class names such as “metadatabylineauthor”, ‘update-time’ etc.
Another issue is that the full text extracted from Beautifulsoup is very buggy since it includes text found in headers, footers, image captions, etc. This is normally avoided when you use a more sophisticated HTML parser such as ones from Specrom Analytics.
Extracting CNN news using Python and Newspaper3k library
Newspaper3k library abstracts lots of complexities of extraction of news articles and lets you directly get the same details by simply querying for a URL.
Its clean and easy interface makes it an attractive choice for web scraping from a preselected list of URLs.
from newspaper import Article
article = Article(test_url)
article.download()
article.parse()
print("Title: ", article.title)
print("Authors: ", article.authors)
print("Date: ", article.publish_date)
Output
Title: Here's how big Facebook's ad business really is
Authors: ['Rishi Iyengar', 'Cnn Business']
Date: 2020-06-30 00:00:00
Extracting CNN News using Python and LXML library
LXML library is written in C with python bindings so it’s about 8-10X faster than the above methods making it ideal for web scraping hundreds of different news articles.
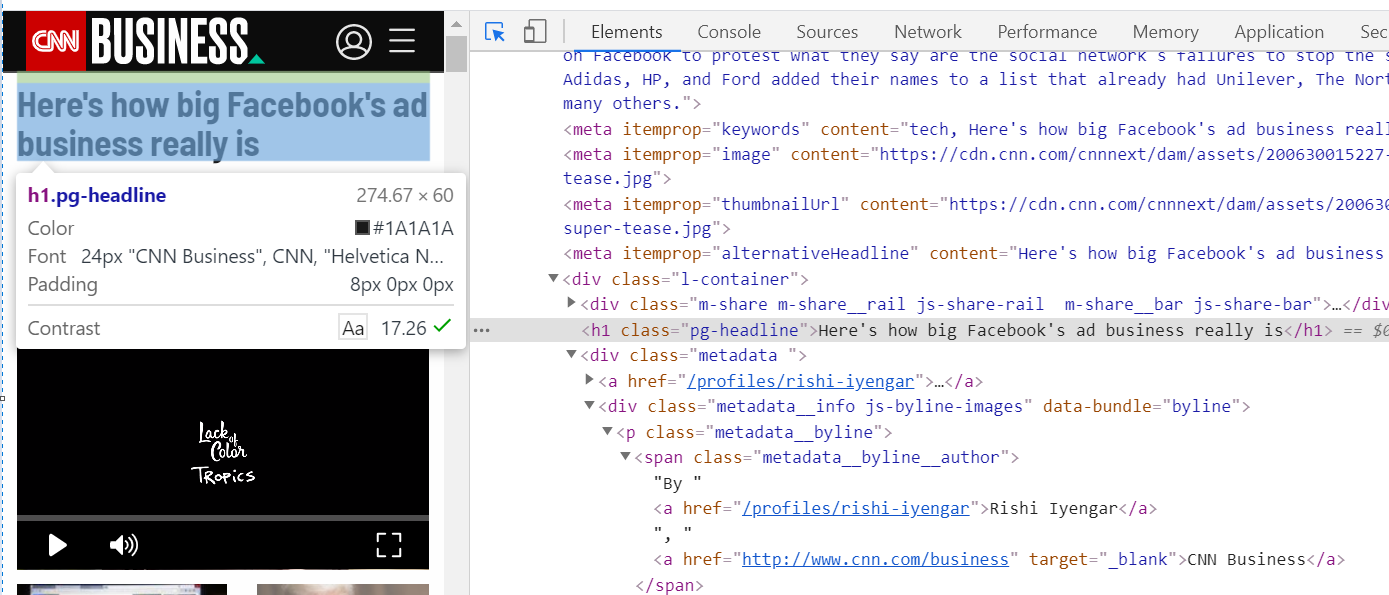
One downside with LXML though is that it requires you to know something known as an XPath to the information you are trying to scrape. This means that you’ll need to go to Google Chrome (or Firefox), click inspect anywhere on the webpage, and select the text area you want to scrape.
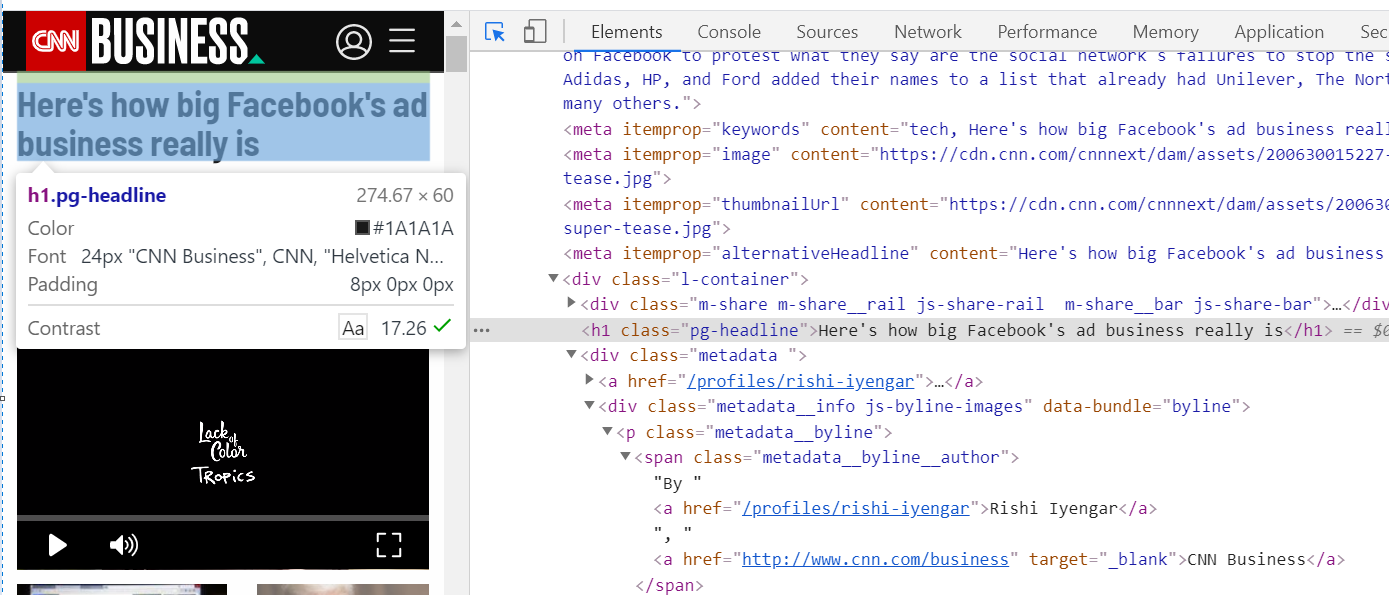
Inspecting html using Google Chrome
Simply right-click on the highlighted portion on the code pane of your browser and select “copy Xpath”.
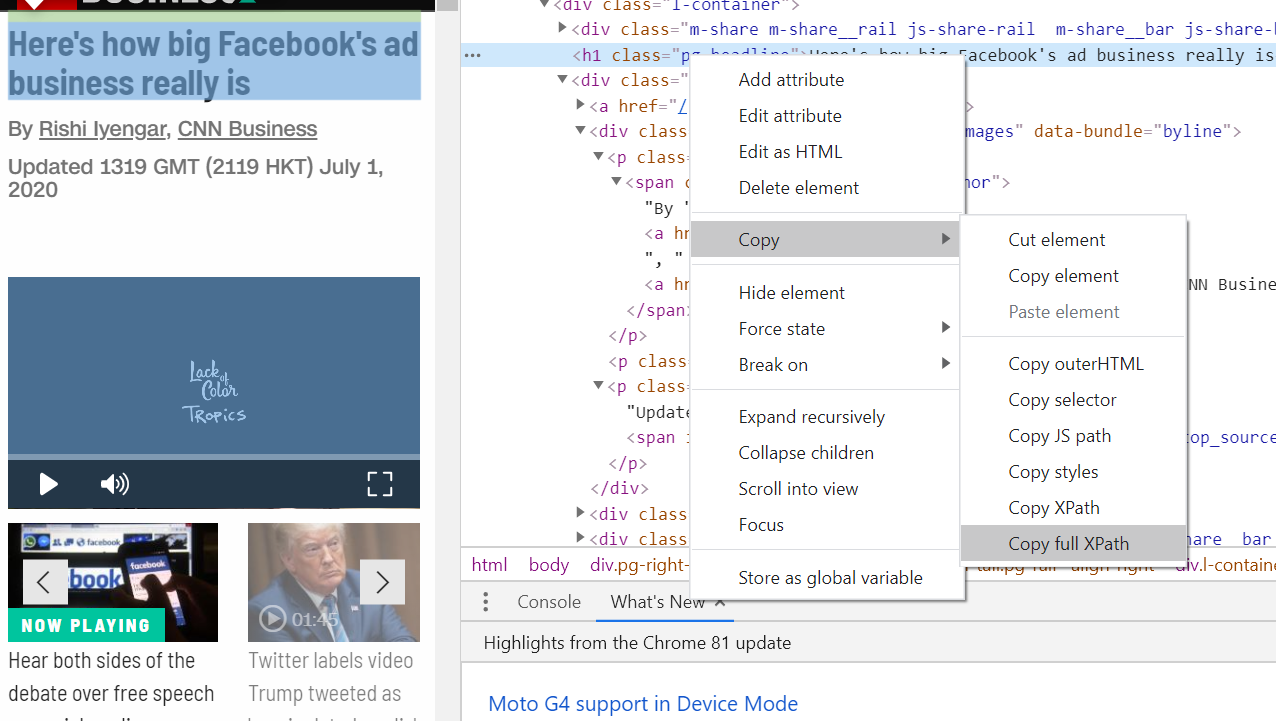
Copying Xpath
You will need to repeat the above steps to get Xpath for Author names, dates, etc. but the general idea remains the same.
Xpath_title = /html/body/div[5]/article/div[1]/h1
from lxml.html import fromstring, tostring
tree = fromstring(html_response)
print(tree.xpath(Xpath_title)[0].text())
One major downside of LXML is that it will only parse well-formed HTML pages; on the other hand, BeautifulSoup is way more resilient about working with badly formed pages.
Managed Web Scraping
One common disadvantage of all the above approaches is that it requires you to explicitly mention the web URL of the page you are trying to scrape. This normally means that you have already put in the effort to manually search for the necessary information either through Google or Bing and now you are just trying to fill out an Excel or CSV file with necessary information.
However, in many cases, you would probably prefer to simply upload a CSV file containing keywords and phrases and output of filled excel file with URLs, author names, titles, etc. The code for this will be way more complicated taking at least 50 developer hours and it will also be very fragile since you will have to update your web scrapers every time there is a change to the structure of the webpage.
In cases like this, it’s perfect to use a managed web scraping service like Specrom’s where you get web scraping results directly to your inbox as excel files with author names, titles, full text, etc. for selected keywords from the news sources you selected. Our free plan gives up to 1000 news articles a month of free data which can easily be scaled up to our most popular plan which gets you 100,000 scraped documents a month for less than $10.