Web scraping TrustRadius reviews
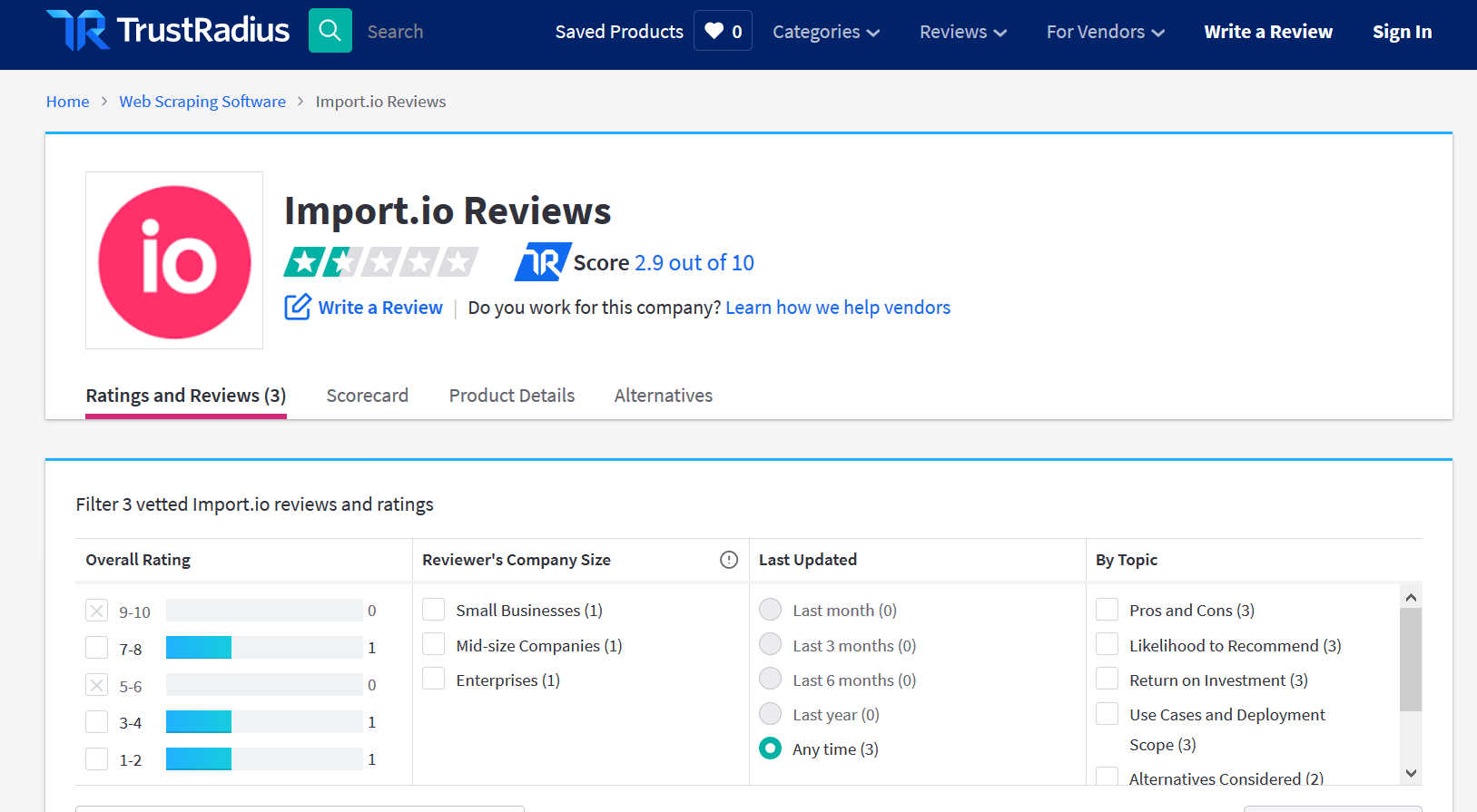
Figure 1: Screenshot of reviews page in TrustRadius.com.
So, what is the easiest way to scrape reviews from TrustRadius.com?
In this article we will try to scrape user reviews for a no code web scraping SAAS service called import.io
At the end of this article, you will be able to extract these reviews as a CSV file.
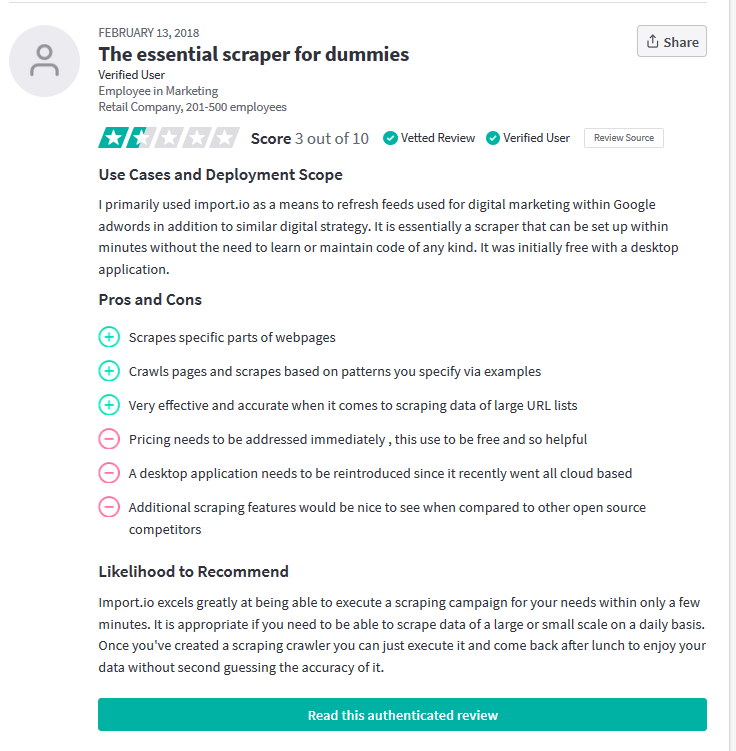
Figure 2: Screenshot of individual review of a product at TrustRadius.com.
Option 1: Hire a fully managed web scraping service.
You can contact us contact us for our fully managed web scraping service to get TrustRadius reviews data as a CSV or excel file without dealing with any coding.
Our pricing starts at $99 for fully managed TrustRadius scraping with upto 10,000 rows/reviews of data.
You can simply sit back and let us handle all complexities of web scraping a site like Google that has plenty of anti-scraping protections built in to try and dissuade from people scraping it in bulk.
We can also create a rest API endpoint for you if you want structured data on demand.
Option 2: Scrape TrustRadius.com on your own
We will use a browser automation library called Selenium to extract data.
Selenium has bindings available in all major programming language so you use whichever language you like, but we will use Python here.
# Extracting TrustRadius.com reviews for Import.io
from selenium import webdriver
import time
from bs4 import BeautifulSoup
url = 'https://www.trustradius.com/products/import-io/reviews'
chrome_option = webdriver.ChromeOptions()
chromedriver = r'chromedriver.exe'
driver = webdriver.Chrome(chromedriver, options=chrome_option)
driver.get(url)
html_source = driver.page_source
driver.close()
Extracting TrustRadius reviews
Extracting review rating
rating_src = soup.find_all('div',{'class','trust-score__score'})
rating = []
for val in rating_src:
try:
rating.append(val.get_text().strip())
except:
pass
rating[:10]
#output
['Score 03 out of 10', 'Score 01 out of 10', 'Score 07 out of 10']
Extracting review title
From inspecting the html source, we see that review date have div tags and belong to class ‘review-title’.
review_title_src = soup.find_all('div',{'class','review-title'})
review_title_details = []
for val in review_title_src:
try:
review_title_details.append(val.get_text())
except:
pass
review_title_details[:10]
#Output
['The essential scraper for dummies',
'Overselling leads to underperformance and way too expensive',
'Use of Connotate for research']
Extracting review date
The next step is extracting review dates of each review.
#Extracting date
datelist_src = soup.find_all('div',{'class','review-date'})
datelist = []
for val in datelist_src:
try:
datelist.append(val.get_text())
except:
pass
datelist[:10]
# Output
['February 13, 2018', 'April 25, 2017', 'August 19, 2014']
Extracting review contents
TrustRadius subdivides its reviews into three sections: Use Cases and Deployment Scope, Pros and cons, and lastly, the likelihood to recommend.
We can extract all the content in one list; however, we will have to separately clean this list esuring that the contents are grouped correctly into these three categories.
firstpara_details_src = soup.find_all('div',{'class','ugc'})
firstpara_details = []
for val in firstpara_details_src:
try:
firstpara_details.append(val.get_text())
except:
pass
firstpara_details[:4]
#Output
['I primarily used import.io as a means to refresh feeds used for digital marketing within Google adwords in addition to similar digital strategy. It is essentially a scraper that can be set up within minutes without the need to learn or maintain code of any kind. It was initially free with a desktop application.',
'Scrapes specific parts of webpagesCrawls pages and scrapes based on patterns you specify via examplesVery effective and accurate when it comes to scraping data of large URL lists',
'Pricing needs to be addressed immediately , this use to be free and so helpfulA desktop application needs to be reintroduced since it recently went all cloud basedAdditional scraping features would be nice to see when compared to other open source competitors',
"Import.io excels greatly at being able to execute a scraping campaign for your needs within only a few minutes. It is appropriate if you need to be able to scrape data of a large or small scale on a daily basis. Once you've created a scraping crawler you can just execute it and come back after lunch to enjoy your data without second guessing the accuracy of it."]
Extracting URL of each review
TrustRadius reviews are very detailed and more information is available on its own page. We can grab the urls of individual reviews by following script.
url_link_src = soup.find_all('a',{'class','link-to-review-btn btn btn-block btn-primary'})
url_link = []
for val in url_link_src:
try:
url_link.append('https://www.trustradius.com'+val['href'])
except:
pass
url_link[:10]
#Output
['https://www.trustradius.com/reviews/import-io-2018-02-12-07-25-00',
'https://www.trustradius.com/reviews/import-io-2017-04-25-15-04-01',
'https://www.trustradius.com/reviews/connotate-2014-08-18-07-44-05']
Converting into CSV file
You can take the lists above, and read it as a pandas DataFrame. Once you have the Dataframe, you can convert to CSV, Excel or JSON easily without any issues.
Scaling up to a full crawler for extracting all TrustRadius reviews of an app
Pagination
- To fetch all the reviews, you will have to paginate through the results.
Implementing anti-CAPTCHA measures
After few dozen requests, the Truspilot servers will start blocking your IP address outright or you will be flagged and will start getting CAPTCHA.
For successfully fetching data, you will have to implement:
- rotating proxy IP addresses preferably using residential proxies.
- rotate user agents
- Use an external CAPTCHA solving service like 2captcha or anticaptcha.com
After you follow all the steps above, you will realize that our pricing for managed web scraping is one of the most competitive in the market.