Web scraping Trustpilot reviews
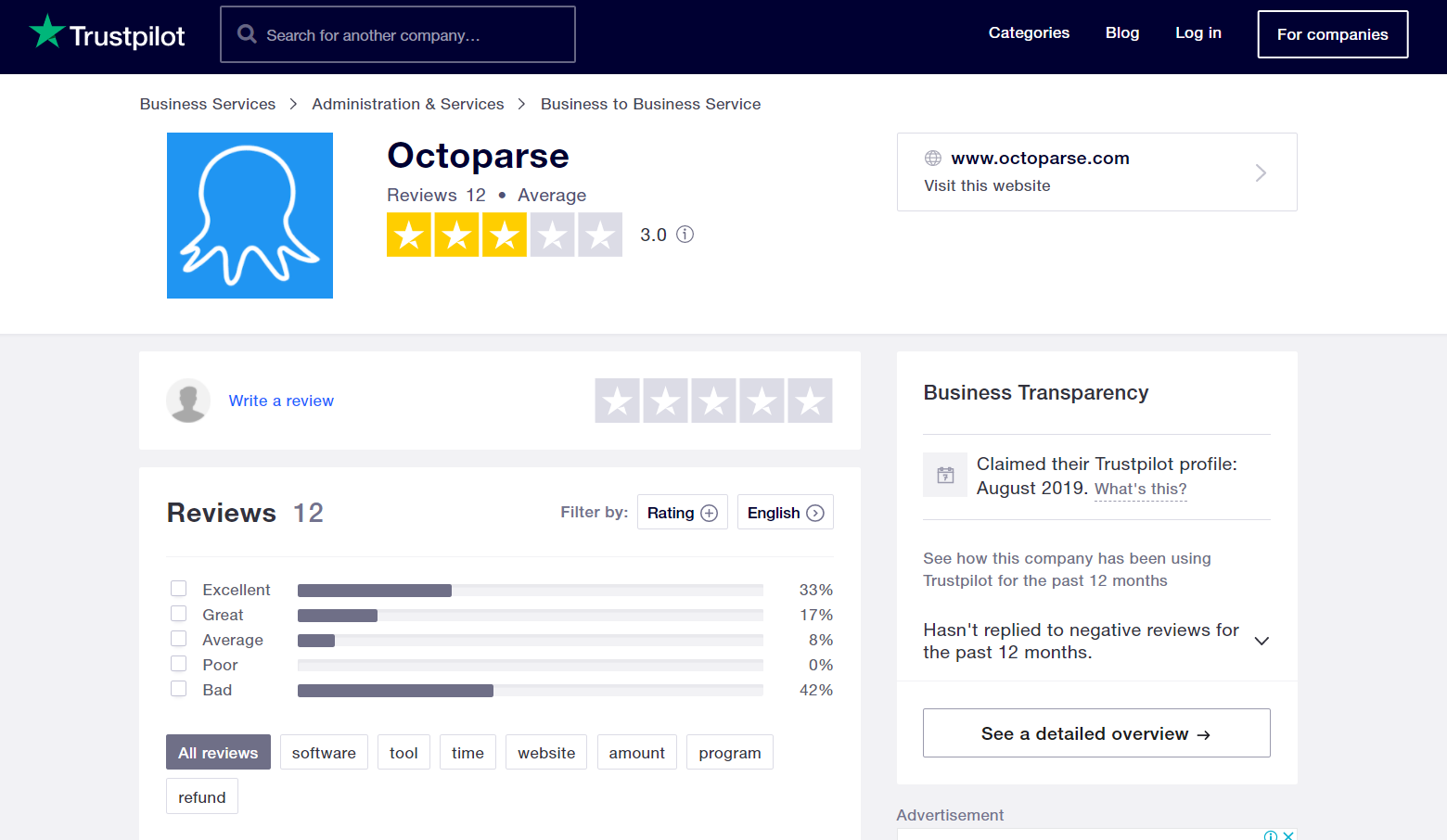
Figure 1: Screenshot of reviews page in Trustpilot.com.
So, what is the easiest way to scrape reviews from Trustpilot.com?
In this article we will try to scrape user reviews for a low code web scraping software called Octoparse.com.
At the end of this article, you will be able to extract these reviews as a CSV file shown in figure 2.
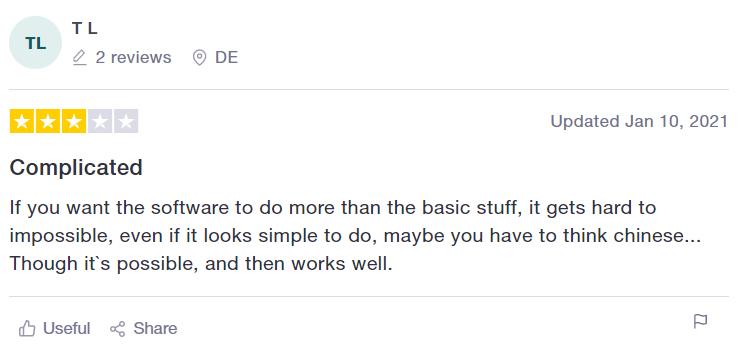
Figure 2: Screenshot of individual review of a product at Trustpilot.com.
Option 1: Hire a fully managed web scraping service.
You can contact us contact us for our fully managed web scraping service to get Trustpilot reviews data as a CSV or excel file without dealing with any coding.
Our pricing starts at $99 for fully managed Trustpilot scraping with upto 20,000 rows of data.
You can simply sit back and let us handle all complexities of web scraping a site like Google that has plenty of anti-scraping protections built in to try and dissuade from people scraping it in bulk.
We can also create a rest API endpoint for you if you want structured data on demand.
Option 2: Scrape Trustpilot.com on your own
We will use a browser automation library called Selenium to extract data.
Selenium has bindings available in all major programming language so you use whichever language you like, but we will use Python here.
# Extracting Trustpilot.com reviews for octoparse.com
from selenium import webdriver
import time
from bs4 import BeautifulSoup
test_url = 'https://www.trustpilot.com/review/www.octoparse.com'
option = webdriver.ChromeOptions()
chromedriver = r'chromedriver.exe'
browser = webdriver.Chrome(chromedriver, options=option)
browser.get(test_url)
html_source = browser.page_source
browser.close()
Extracting Trustpilot reviews
Once we have the raw html source, we should use a Python library called BeautifulSoup for parsing the raw html files.
Extracting review author
From inspecting the html source, we see that review authors have div tags and belong to class ‘consumer-information__name’.
# extracting authors
soup=BeautifulSoup(html_source, "html.parser")
review_author_list_src = soup.find_all('div', {'class','consumer-information__name'})
review_author_name_list = []
for val in review_author_list_src:
try:
review_author_name_list.append(val.get_text())
except:
pass
review_author_name_list[:3]
#Output
['flavio',
'Cici Wu',
'T L',
'Phil Caulkins',
'Putra',
'sendak',
'Aisha Mohamed',
'Milly Fang',
'Chris �MeatStream� Walker',
'Ashley Han',
'Jiahao Wu',
'Frank Parker']
Extracting review date
The next step is extracting review dates of each review.
# extracting review dates
date_src = soup.find_all('time')
date_src
date_list = []
for val in date_src:
date_list.append(val.get_text())
date_list
# Output
['2021-04-16',
'2021-03-22',
'2021-01-10',
'2020-12-02',
'2020-11-15',
'2020-10-10',
'2020-07-30',
'2020-05-28',
'2020-03-12',
'2019-11-25',
'2019-08-27',
'2019-08-22']
Extracting review title and review contents
For brevity we will only show results from first five results, and you can verify that the first result matches the text in figure 2 above.
# extracting review title
review_title_src = soup.find_all('h2',{'class', 'review-content__title'})
review_title_list = []
for val in review_title_src:
review_title_list.append(val.get_text())
print(review_title_list[:3])
# extracting review content
review_content_src = soup.find_all('div',{'class', 'UD7Dzf'})
review_content_list = []
for val in review_content_src:
review_content_list.append(val.get_text())
review_content_list[:3]
# Output
['the software is janky and takes some�',
'Nice tool to get great amount of web data',
'Complicated',
'the programs are written in chinese-�',
'Impossible to Refund & One of the Worst Software']
***
['the software is janky and takes some time to master. however, the customer support was super helpful. they were responsive and even troubleshoot my task in order to make it work properly.',
'There are transparent pricing and reminder emails so I am not confused about the payment issue. I want to recommend it if you are not a programmer, and want to gather a great number of data for analysis and research. This software is easier and more friendly to people who cannot code, and you can collect info from multiple websites, into a structured spreadsheet. This tool just tremendously improves my efficiency while conducting my research. Thanks a lot!',
'If you want the software to do more than the basic stuff, it gets hard to impossible, even if it looks simple to do, maybe you have to think chinese... Though it`s possible, and then works well.',
'the programs are written in chinese- the reviews are fake- they dont return the funs and Paypal is closing their account but they keep on opening new ones with new email address. CHINESE SCAM',
'First they will make your refund almost impossible to get, if you pay through paypal. they refund you very small amount to make paypal detects that you already got refunded. I mean what kind of software cost this much per month\n\nSecond, I have use their software, they ONLY can extract website with consistent amount of div, (but most data heavy website is an ugly ones). So it is very useless software. \n\nIm still unable to extract good data from the government.. so with that prices, better not']
Converting into CSV file
You can take the lists above, and read it as a pandas DataFrame. Once you have the Dataframe, you can convert to CSV, Excel or JSON easily without any issues.
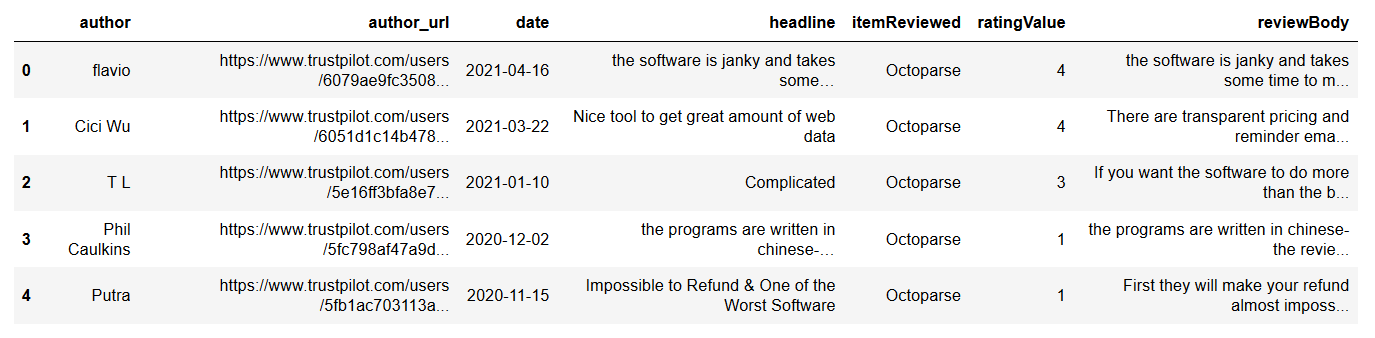
Figure 3: Screenshot of Trustpilot.com reviews saved as a CSV file.
Scaling up to a full crawler for extracting all Trustpilot reviews of an app
Pagination
- To fetch all the reviews, you will have to paginate through the results.
Implementing anti-CAPTCHA measures
After few dozen requests, the Truspilot servers will start blocking your IP address outright or you will be flagged and will start getting CAPTCHA.
For successfully fetching data, you will have to implement:
- rotating proxy IP addresses preferably using residential proxies.
- rotate user agents
- Use an external CAPTCHA solving service like 2captcha or anticaptcha.com
After you follow all the steps above, you will realize that our pricing for managed web scraping is one of the most competitive in the market.