Web Scraping Amazon Products Page
Amazon is the largest ecommerce platform in the world, and if you are selling a product, than chances are that you or your competitors are already on Amazon.
In the article we will use Python to scrape individual Amazon product page and extract title, review count, product description etc.
We offer a complete web scraping service where you can get over 20,000 products data from Amazon either as a CSV, Excel or as a API for only $99.
However, if you want to do it yourself then continue reading rest of the article.
Fetching the Amazon.com product page
We will use Python package called requests and Beautifulsoup to fetch and parse a random product page from Amazon.
import requests
from bs4 import BeautifulSoup
query_url = 'https://www.amazon.com/Just-Smarty-Interactive-Educational-Kindergarten/dp/B074PYYM51/ref=dp_prsubs_1?pd_rd_i=B074PYYM51&psc=1'
r = requests.get(url)
if r.status_code == 200:
html_source= r.text
soup = BeautifulSoup(html_source, "html.parser")
Just for reference, we will also click inspect in Chrome browser and look at the source.
Our goal is to look at class names and attributes so that we can use it for extracting individual fields.
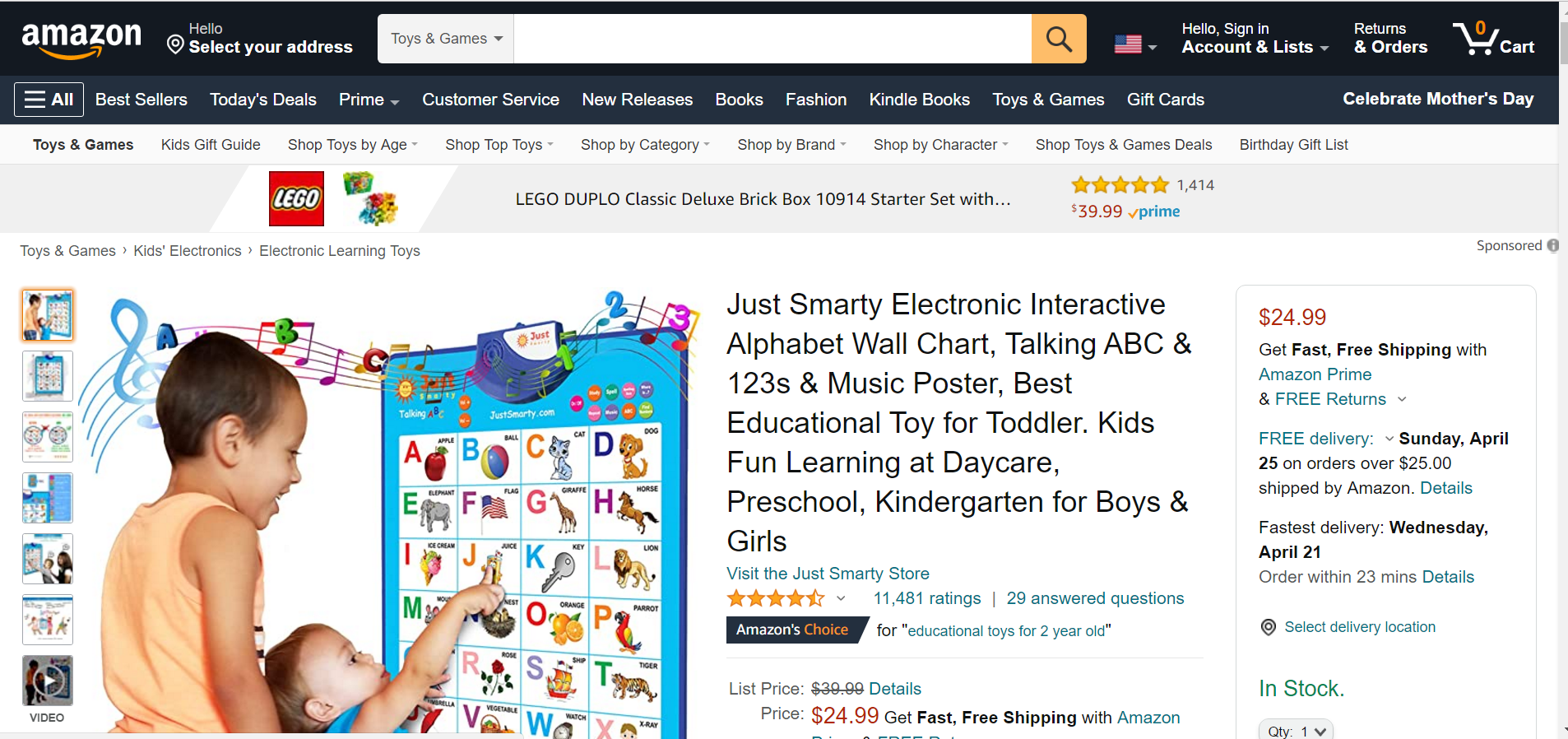
Figure 1: Inspecting the source of a product page on Amazon.com.
Extracting title
# extracting title
title = soup.find("span", attrs={"id":'productTitle'})
title_value = title.string
title_string = title_value.strip()
title_string
#Output
'Just Smarty Electronic Interactive Alphabet Wall Chart, Talking ABC & 123s & Music Poster, Best Educational Toy for Toddler. Kids Fun Learning at Daycare, Preschool, Kindergarten for Boys & Girls'
Extracting product description
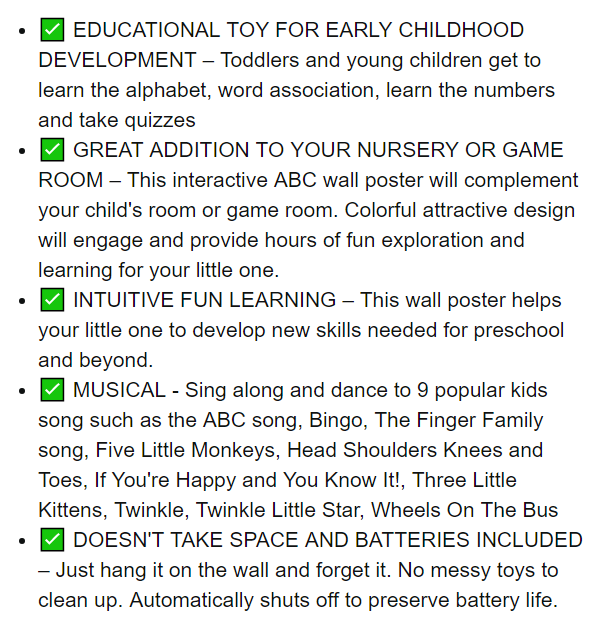
Figure 2: Product description on Amazon.com.
From the inspect tab, we notice that the description belongs to feature-bullets ul.a-unordered-list. Let us use the findAll method to extract it.
# extracting product description
features = []
for li in soup.select("#feature-bullets ul.a-unordered-list")[0].findAll('li'):
features.append(li.get_text().strip())
features
#Output
['Make sure this fits\nby entering your model number.',
'✅ EDUCATIONAL TOY FOR EARLY CHILDHOOD DEVELOPMENT – Toddlers and young children get to learn the alphabet, word association, learn the numbers and take quizzes',
"✅ GREAT ADDITION TO YOUR NURSERY OR GAME ROOM – This interactive ABC wall poster will complement your child's room or game room. Colorful attractive design will engage and provide hours of fun exploration and learning for your little one.",
'✅ INTUITIVE FUN LEARNING – This wall poster helps your little one to develop new skills needed for preschool and beyond.',
"✅ MUSICAL - Sing along and dance to 9 popular kids song such as the ABC song, Bingo, The Finger Family song, Five Little Monkeys, Head Shoulders Knees and Toes, If You're Happy and You Know It!, Three Little Kittens, Twinkle, Twinkle Little Star, Wheels On The Bus",
"✅ DOESN'T TAKE SPACE AND BATTERIES INCLUDED – Just hang it on the wall and forget it. No messy toys to clean up. Automatically shuts off to preserve battery life."]
Get review count and review star rating
Amazon reviews and rating count is a great way to understand how popular a product historically has been with the consumers. Note that bestseller ranking (BSR) captures how the product is selling today relative to its peers but review count tells us how well it has done since it was launched.
There is lot of research that has shown that a higher aggregate review count typically denotes strong BSR ranking over a longer duration of time.
def get_review_count(soup):
try:
review_count = soup.find("span", attrs={'id':'acrCustomerReviewText'}).string.strip()
except AttributeError:
review_count = ""
return review_count
get_review_count(soup)
#Output
'11,481 ratings'
The count by itself doesn’t convey whether customers liked a product or not. For that, we have to look at aggregate star rating.
def get_rating(soup):
try:
rating = soup.find("i", attrs={'class':'a-icon a-icon-star a-star-4-5'}).string.strip()
except AttributeError:
try:
rating = soup.find("span", attrs={'class':'a-icon-alt'}).string.strip()
except:
rating = ""
return rating
get_rating(soup)
#Output
'4.5 out of 5 stars'
Extracting product categories and bestseller rankings
Amazon assigns product categories and subcategories for each products. Let us first grab the product category.
categories = []
for li in soup.select("#wayfinding-breadcrumbs_container ul.a-unordered-list")[0].findAll("li"):
categories.append(li.get_text().strip())
categories
#output
['Toys & Games', '›', "Kids' Electronics", '›', 'Electronic Learning Toys']
Similarly, we can extract product bestseller rankings
# product best seller ranking
table_item = soup.find('table',{'id':'productDetails_detailBullets_sections1'})
table_rows = table_item.find_all('tr')
for row in table_rows:
if 'Best Sellers Rank' in row.find('th').get_text():
print(row.find('td').get_text())
#Output
#196 in Toys & Games (See Top 100 in Toys & Games)
#2 in Toddler Learning Toys
#3 in Electronic Learning & Education Toys
#8 in Preschool Learning Toys
Extract price from buybox
Finally, we need to extract the price of the product.
def get_price(soup):
try:
price = soup.find("span", attrs={'id':'priceblock_ourprice'}).string.strip()
except AttributeError:
price = ""
return price
get_price(soup)
#Output
$24.99
Scaling up to a full crawler for extracting thousands of Amazon product pages
Once you have the above scraper that can extract data for one product page you will need to modify the code to generate URL patterns based on product identifiers such as ASIN or UPC, EIN numbers.
Amazon has hundreds of slightly different product pages with schema that varies slightly due to continous A/B testing. Hence, you may notice that the scraper above isn’t able to extract data from all product pages. In production setting, we run a prefilter that detects the type of product page and triggers the correct extractor function.
Amazon is notorious about blocking scrapers from extracting product pages by giving lots of CAPTCHA.
To make it more likely to successfully fetch data for all USA, you will have to implement:
- rotating proxy IP addresses preferably using residential proxies.
- rotate user agents
- Use an external CAPTCHA solving service like 2captcha or anticaptcha.com
After you follow all the steps above, you will realize that our pricing($99) for getting complete data for upto 20,000 product pages from Amazon is pretty competitive.