Web scraping Google chrome web store extension user reviews
So, what is the easiest way to extract elements such as review content, date, author, star rating from reviews at chrome web store extension ?
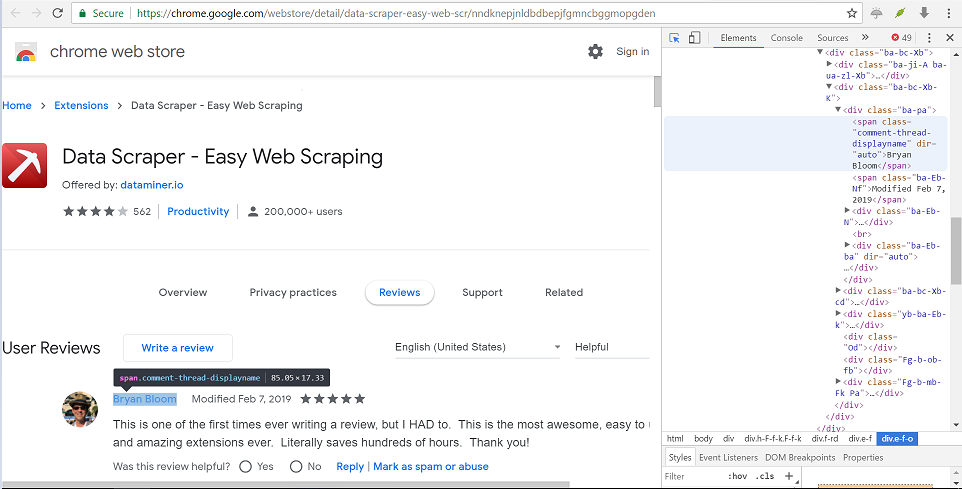
Figure 1: Screenshot of Google chrome web store extension reviews.
At the end of this article, you will be able to extract these individual elements highlighted in red in figure 2.

Figure 2: Screenshot of important elements to extract from individual Google chrome web store user review.
Option 1: Hire a fully managed web scraping service.
You can contact us contact us for our fully managed web scraping service to get chrome web store extension reviews data as a CSV or excel file without dealing with any coding.
Our pricing starts at $99 for fully managed Google chrome web store scraping.
You can simply sit back and just give us a list of chrome extension urls or ids and let us handle all complexities of web scraping a site like Google that has plenty of anti-scraping protections built in to try and dissuade from people scraping it in bulk.
We can also create a rest API endpoint for you if you want structured data on demand.
Option 2: Scrape Google chrome web store extension reviews on your own
We will use a browser automation library called Selenium to extract results for the a particular extension in chrome web store.
Selenium has bindings available in all major programming language so you use whichever language you like, but we will use Python here.
# Using Selenium to extract Chrome web store reviews
from selenium import webdriver
import time
from bs4 import BeautifulSoup
test_url = 'https://chrome.google.com/webstore/detail/data-scraper-easy-web-scr/nndknepjnldbdbepjfgmncbggmopgden'
option = webdriver.ChromeOptions()
option.add_argument("--incognito")
chromedriver = r'chromedriver.exe'
browser = webdriver.Chrome(chromedriver, options=option)
browser.get(test_url)
html_source = browser.page_source
Parsing individual fields
Let us parse basic information such as extension name, total users, and aggregate rating value.
Extracting basic information about the extension
# extracting chrome extension name
soup=BeautifulSoup(html_source, "html.parser")
print(soup.find_all('h1',{'class','e-f-w'})[0].get_text())
total_users = soup.find_all('span',{'class','e-f-ih'})[0].get_text()
print(total_users.strip())
total_reviews = soup.find_all('div',{'class','nAtiRe'})[0].get_text()
print(total_reviews.strip())
# rating value
meta=soup.find_all('meta')
for val in meta:
try:
if val['itemprop']=='ratingValue':
print(val['content'])
except:
pass
#Output
'Data Scraper - Easy Web Scraping'
'200,000+ users'
'562'
4.080071174377224
Once we have the basic information, we will click on the reviews tab programmatically so that we can load all the reviews and scroll till the end of the page.
# clicking reviews button
element = browser.find_element_by_xpath('//*[@id=":25"]/div/div')
element.click()
time.sleep(5)
# scrolling till end of the page
from selenium.webdriver.common.keys import Keys
html = browser.find_element_by_tag_name('html')
html.send_keys(Keys.END)
html_source = browser.page_source
browser.close()
soup=BeautifulSoup(html_source, 'html.parser')
Extracting review author names
Let’s extract review author names.
review_author_list_src = soup.find_all('span', {'class','comment-thread-displayname'})
review_author_name_list = []
for val in review_author_list_src:
try:
review_author_name_list.append(val.get_text())
except:
pass
review_author_name_list[:10]
#Output
['Bryan Bloom',
'Sudhakar Kadavasal',
'Lauren Rich',
'�yvind Andr� Sandberg',
'Paul Adamson',
'Phoebe Staab',
'Frank Mathmann',
'Bobby Thomas',
'Kevin Humphrey',
'David Wills']
Extracting review date
The next step is extracting review dates of each review.
# extracting review dates
date_src = soup.find_all('span',{'class', 'ba-Eb-Nf'})
date_src
date_list = []
for val in date_src:
date_list.append(val.get_text())
date_list[:10]
# Output
['Modified Feb 7, 2019',
'Modified Jan 8, 2019',
'Modified Dec 31, 2018',
'Modified Jan 4, 2019',
'Modified Dec 14, 2018',
'Modified Feb 5, 2019',
'Modified Dec 13, 2018',
'Modified Jan 16, 2019',
'Modified Nov 29, 2018',
'Modified Nov 16, 2018']
Extracting review star rating
You can perform sentiments analysis on review contents, but its generally a good idea to use the star rating of the review itself for a weighted average on the sentiments, if the sentiments fall in neutral area, or alternately, just use the star rating for calibration of your text sentiments analysis model itself if you are in model development.
# extracting review star rating
star_rating_src = soup.find_all('div', {'class','rsw-stars'})
star_rating_list = []
for val in star_rating_src:
try:
star_rating_list.append(val['aria-label'])
except:
pass
star_rating_list[:10]
# Output
['5 stars',
'5 stars',
'5 stars',
'5 stars',
'5 stars',
'5 stars',
'5 stars',
'2 stars',
'5 stars',
'5 stars']
Extracting review contents
For brevity we will only show results from first three results, and you can verify that the first result matches the text in figure 2 above.
# extracting review content
review_content_src = soup.find_all('div',{'class', 'ba-Eb-ba'})
review_content_list = []
for val in review_content_src:
review_content_list.append(val.get_text())
review_content_list[:3]
# Output
['This is one of the first times ever writing a review, but I HAD to. This is the most awesome, easy to use and amazing extensions ever. Literally saves hundreds of hours. Thank you!',
'Loved it. It automatically detected the data structure suited for the website and that helped me in learning how to use the tool without having to read the tutorial! Beautifully written tool. Kudos.',
'Great tool for mining data. We used Data Miner to extract data from the Medicare.gov website for an upcoming mailing to nursing homes and assisted living facilities. It can comb through a number of pages in a matter of seconds, extracting thousands of rows into one concise spreadsheet. I would highly recommend this product to any business looking to obtain data for any purpose - mailing, email campaign, etc. Thank you Data Miner!']
Converting into CSV file
You can take the lists above, and read it as a pandas DataFrame. Once you have the Dataframe, you can convert to CSV, Excel or JSON easily without any issues.
Scaling up to a full crawler for extracting all google chrome web store reviews of an app
Pagination
- To fetch all the reviews, you will have to paginate through the results.
Implementing anti-CAPTCHA measures
After few dozen requests, the Google.com servers will start blocking your IP address outright or you will be flagged and will start getting CAPTCHA.
For successfully fetching data, you will have to implement:
- rotating proxy IP addresses preferably using residential proxies.
- rotate user agents
- Use an external CAPTCHA solving service like 2captcha or anticaptcha.com
After you follow all the steps above, you will realize that our pricing for managed web scraping is one of the most competitive in the market.