Relational Databases and SQL
Why should we care about SQL and relational databases
It doesn’t matter if you are running a small business website like a restaurant or running a deep 10,000 page content site and monetizing using affiliate marketing, ads or other approaches, the truth is that the data you create or interact with lives in relational databases in some part of its journey from data creation to user engagement/consumption.
Wordpress and other CMSes use MySQL or PostgreSQL as their backend servers.
In some use cases, we store raw web scraping data JSONs in a NoSQL database such as MongoDB and after using our Text Analytics APIs, which outputs nice clean data useful for lead generation such as contact person name, phone numbers, email addresses etc, we will take that and load it to a relational database in cases where client doesn’t just want to use Excel or CSV files.
In either of those cases, relational databases are integral part of most data ingestion pipelines.
What are relational databases?
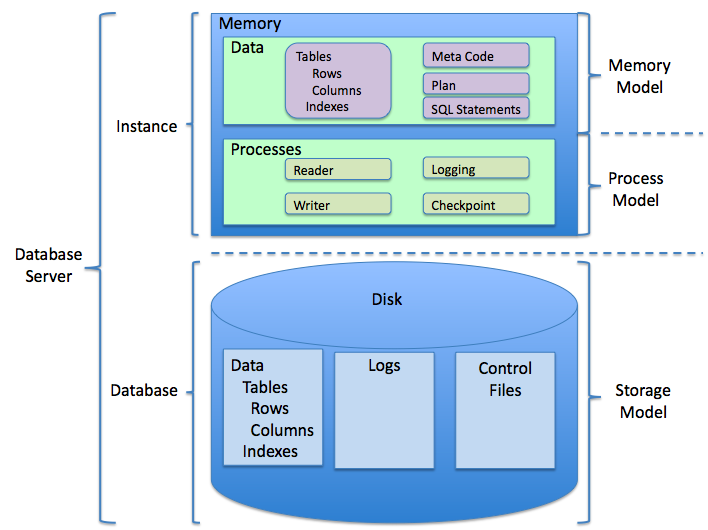
Relational Databases organize data in rows and tables like a printed mail order catalog or a train schedule list. They are specifically optimized for indexing large amounts of data for quick retrieval. Most relational databases are handled by database server, an application designed specifically for managing databases, and which is responsible for abstracting low level details of accessing the underlying data. Relational database management system is based on the relational model invented by Edgar F. Codd, of IBM’s San Jose Research Laboratory. Most databases in widespread use are based on the relational database model but there are few which don’t fit this description and we will talk about them in the next section.
One of the most common data model in known as ACID which stands for Atomaticity, Consistency, Isolation and Durability.
Atomicity means that database modifications must follow an all or nothing rule where if one part of the transaction fails, the entire transaction fails. Each transaction is said to be atomic. A database management system should maintains the atomic nature of transactions in spite of any DBMS, operating system or hardware failure.
Consistency means that only valid data will be written to the database and all the changes made by a transaction must leave the database in a valid state as defined by any constraints and other rules. If a transaction is executed that violates the database’s consistency rules, the entire transaction will be rolled back, and the database will be restored to a state consistent with those rules.
Isolation requires that multiple transactions occurring at the same time not impact each others execution.
Durability ensures that any transaction committed to the database will not be lost or rolled back.
MySQL
MySQL is a very popular open-source RDBMS originally developed by Swedish company MySQL AB which was acquired by Sun microsystems which was later acquired by Oracle Corporation. Even though MySQL is distributed under dual license (open source and proprietary) there were concerns in the community on the further development of MySQL after acquisition by Oracle Corporation and they created a community-developed fork called MariaDB intended to remain free under the GNU GPL. We are going to use MySQL to illustrate SQL queries and refer to appendix to see how to install it.
Storage engines are MySQL components that handle the SQL operations for different table types. InnoDB is the default and most general-purpose storage engine, and it is recommended by Oracle except for specialized use cases. The CREATE TABLE statement in MySQL creates InnoDB tables by default.
InnoDB: The default storage engine in MySQL 5.7. InnoDB is a transaction-safe (ACID compliant) storage engine for MySQL that has commit, rollback, and crash-recovery capabilities to protect user data. InnoDB row-level locking (without escalation to coarser granularity locks) and Oracle-style consistent nonlocking reads increase multi-user concurrency and performance. InnoDB stores user data in clustered indexes to reduce I/O for common queries based on primary keys. To maintain data integrity, InnoDB also supports FOREIGN KEY referential-integrity constraints.
MyISAM: This was the default storage engine prior to MySQL 5.5 and and is not ACID compliant. Table-level locking limits the performance in read/write workloads, so it is often used in read-only or read-mostly workloads in Web and data warehousing configurations.
Memory: Stores all data in RAM, for fast access in environments that require quick lookups of non-critical data. This engine was formerly known as the HEAP engine. Its use cases are decreasing; InnoDB with its buffer pool memory area provides a general-purpose and durable way to keep most or all data in memory, and NDBCLUSTER provides fast key-value lookups for huge distributed data sets.
CSV: Its tables are really text files with comma-separated values. CSV tables let you import or dump data in CSV format, to exchange data with scripts and applications that read and write that same format. Because CSV tables are not indexed, you typically keep the data in InnoDB tables during normal operation, and only use CSV tables during the import or export stage.
MyISAM and InnoDB are the most commonly used engines and should work in most situations. However, for a complete list of all available engines, please refer to https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html
We recommend that you install the MySQL workbench which will allow you to visually play with SQL queries and model the data in a user friendly way.
Structured Query Language (SQL)
Structured Query Language (SQL) is a domain-specific language used in programming and designed for managing data held in a RDBMS, or for stream processing in a relational data stream management system (RDSMS).
SQL became a standard of the American National Standards Institute (ANSI) in 1986, and of the International Organization for Standardization (ISO) in 1987, however, not all the features from the standard are implemented in different database systems and hence SQL code is not completely portable across different RDSMS such as Oracle, MySQL, PostgreSQL, Microsoft SQL server.
In this section, we are going to use ANSI-SQL as much as possible with mysql and explicitly highlight if commands we use differ across different RDBMS implementations.
The data entered in a SQL database is case sensitive, but the SQL statements are not, and to improve readability, they are written in uppercase.
The following are just a list of important conventions while writing SQL queries:
- As mentioned in earlier paragraph, type SQL keywords in uppercase
- Name identifiers such as tables, column names etc in lowercase and avoid picking reserve words.
- Single column primary key fields should end with id
- Foreign key fields should be a combination of the name of the referenced table and the name of the referenced fields
SQL can be divided into following categories:
Data control language
CREATE USERallows the creation of a new userGRANTallows assignment of privelidges to a specific userALTERREVOKE
Data definition language
CREATEallows the user to create databases, tables, views and index.ALTERallows the user to change the definition of an existing table or index.DROPallows the user to delete entire databases, tables and views.
Data manipulation language
INSERT INTOallows the user to add records to a tableUPDATEallows the user to update existing records in a tableDELETEallows the user to delete existing records from a table
The following are transactional commands:
START TRANSACTIONstarts a transactionCOMMITSaves database transactionsROLLBACKUndoes database transactionsSAVEPOINTCreates points within groups of transactions in which to ROLLBACKSET TRANSACTIONSpecifies transaction characteristics (such as read only, or read and write)
Data query language
This is arguably the most important part SQL for our purposes, and we will spend the most time on it in this section.
USEallows the user to specify a databaseSELECTallows the user to retrieve existing records from a table
Let us look at each of these subcategories in greater detail below.
Data control language
Login to your MySQL by
mysql -u root -p
Create new user “jmp1” with password “jmppassword”; MySQL considers each username/hostname pair to be a separate account. We can use wildcards to get partial name match in hostname. “_” matches a single character and “%” matches any number of characters.
CREATE USER 'jmp1'@'localhost' IDENTIFIED BY 'jmppassword';
New accounts in MySQL have no privileges associated with the account, and they can be assigned by GRANT. The asterisks in this command refer to the database and table (respectively) that jmp1 can access; If you only want to give access to any tables within database “firstdatabase”, you can instead write firstdatabase.*
GRANT CREATE, DROP, ALTER, INSERT, UPDATE, SELECT, DELETE,
INDEX ON *.* TO 'jmp1'@'localhost';
alternately you can also use this statement:
GRANT ALL PRIVILEGES ON *.* TO 'jmp1'@'localhost';
Privileges can be revoked by using REVOKE statement
REVOKE CREATE, DROP, ALTER, INSERT, UPDATE, SELECT, DELETE,
INDEX ON *.* TO 'jmp1'@'localhost';
No user/privilege related changes are applied until MySQL server is restarted. To force MySQL to reload the cache, use
FLUSH PRIVILEGES;
Data definition language
This deals with creation or modification of database objects such tables, views and index.
Data Types
MySQL has INTEGER, TINYINT, SMALLINT, MEDIUMINT and BIGINT data types for storing integer data and could be UNSIGNED or SIGNED.
DECIMAL, FLOAT, and DOUBLE are used for real numbers and require the user to specify precision (the number of total digits) and scale (the number of digits that follow the decimal point) for example DECIMAL (5,3) means -99.999 to 99.999.
Text data can be stored as CHAR, VARCHAR, BINARY, VARBINARY, TEXT, TINYTEXT, MEDIUMTEXT, LONGTEXT, BLOB, TINYBLOB, MEDIUMBLOB, and LONGBLOB.
There are also datatypes for time, year, and spatial data types for storing geographic information. For more information on data types, check out the reference manual here https://dev.mysql.com/doc/refman/5.7/en/data-types.html
User specified datatypes are also possible as shown below.
CREATE TYPE PERSON AS OBJECT
(FIRST_NAME VARCHAR (30),
LAST_NAME VARCHAR (30),
SSN VARCHAR (9));
They can be directly referenced in CREATE TABLE statement.
CREATE TABLE CUSTOMER_INFO
(CUSTOMER PERSON,
TOTAL_ORDERS DECIMAL(10,2),
CUSTOMER_SINCE DATE);
Creating a new database (CREATE DATABASE)
In MySQL this can be done by
CREATE DATABASE new_database
-- "SCHEMA" is a synonym for "DATABASE" in MySQL, so this works too:
CREATE SCHEMA new_database
Select a database by using USE
USE new_database
Creating a new table (CREATE TABLE)
A new table named pet can be created by using the CREATE TABLE
CREATE TABLE pet (
name_id INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,
species VARCHAR(20),
sex CHAR(1),
birth DATE,
email VARCHAR(100) NOT NULL,
PRIMARY KEY (name_id),
INDEX (name),
UNIQUE (email)
)
ENGINE=InnoDB;
CREATE TABLE AS SELECT method is supported by MySQL.
create table new_table_name as
select [ * | column1, column2 ]
from table_name
[ where ]
A primary key constraint uniquely identifies each rows in a table and any column with unique data can be set as primary keys such as column containing social security numbers.
A foreign key is a column in a child table that references a primary key in the parent table. This constraint helps cross-referenced data consistent across tables.
Data Manipulation Language
This deals with adding or inserting, updating and deleting data in a database.
Inserting data into tables (INSERT INTO)
Data can be added in a table by using INSERT INTO statement. Single quotation marks are required for enclosing character and date/time data types; its not needed for NULL and numeric type.
INSERT INTO table_name
VALUES ('value1', 'value2',...);
The statement above will insert data into columns in the same order in which the columns were initially created. Its better to explicitly specify the column names where the data is to be inserted.
INSERT INTO table_name
(col_name_1, col_name_2,...)
VALUES ('value1', 'value2',...);
INSERT INTO pet
(species, sex, birth, email)
VALUES
('bulldog', 'm', '2014-12-15', 'jaypatel@example.com');
To verify that data is added
SELECT * FROM pet
Transactions
The changes in the database occurs as soon as the statements above are executed and they cannot be rolled back; this is called the autocommit mode which is also default in MySQL. To disable this mode, you can use transactions, which allows functionalities such as rollback the last transaction entirely, or to a predefined point known as savepoint. Note that some statements cannot be rolled back such as create or drop databases or tables ref https://dev.mysql.com/doc/refman/8.0/en/cannot-roll-back.html
To start a transaction use and make a change:
START TRANSACTION;
SELECT col_1 FROM table_1 WHERE type=1;
UPDATE table2 SET XYZ WHERE type=1;
COMMIT;
Data Query language
Read-only selecting of data is performed by DQL commands of SQL. See all the databases by using SHOW DATABASES and SHOW TABLES is used to see all tables.
Pick a particular database using:
USE database_name
Selecting data (SELECT TABLE using FROM, WHERE)
To select a table from a particular database, you have to append database name in front of table name
SELECT *
FROM database_name.table_1;
Alternatively, if a particular database is already in use using USE command (USE database-name) than you can just mention the table name
SELECT *
FROM table_1;
Use the keyword SELECT DISTINCT to specify nonduplicate values.
AS
We can create an alias for any table name or column name by using AS command. For example, SELECT col_1 AS SALARY
Lets switch to one of the example databases available in MySQL called sakila.
WHERE
Use the operators below with WHERE statement to get specific results from the SELECT statement above.
Comparison operators
These include =, >, <, <=, >= and non equality (!= and <>).
Logical operators
NOT EQUAL(alias!=,<>)IS NULLandIS NOT NULLBETWEENandNOT BETWEENINandNOT INLIKEandNOT LIKE(with%for 0-multiple characters and_for single characters)EXISTSandNOT EXISTSUNIQUEandNOT UNIQUEALLreturns TRUE only if all rows meet subquery condition.ANY(aliasSOME)
Arithmetic operators
SQL supports multiple arithmetic operators to perform addition, subtraction, division, and multiplication.
SELECT payment_id, amount, amount*10+1000/100 AS modified_amount
FROM payment
WHERE payment_id BETWEEN 1 AND 20;
Summarizing/aggregating data (COUNT, ….) and sorting
The general format is
SELECT [Summary operator] col_name1, [Summary operator] col_name2
FROM table_name
WHERE XXX
GROUP BY col_name1, col_name2
HAVING XYZ
ORDER BY col_name1, col_name2;
COUNT()use COUNT (*) or COUNT ALL to get everything or COUNT DISTINCT to get nonduplicateMAX()MIN()SUM()AVG()GROUP BYif you have selected multiple columns to aggregate, then this allows you to specify the column order of the output (NOTE: all non aggregate columns must be listed in GROUP BY statement)ROLLUPhttps://dev.mysql.com/doc/refman/8.0/en/group-by-modifiers.htmlHAVING: This is analogous WHERE used in select, and here it’s used to restrict groups created by GROUP BY statement.CUBENot available in MySQL
ORDER BY
ORDER BY
The default behavior is ascending order (ASC), descending order can be specified explicitly by the keyword DESC at the end of the order by clause. In case of ordering by multiple columns, specify the DESC and ASC keywords next to each column name as shown in example below (only 20 rows selected). We can use numbers in ORDER BY clause to refer to columns without typing them out explicitly.
SELECT first_name, last_name, actor_id, COUNT (last_name) AS COUNT
FROM ACTOR
WHERE actor_id BETWEEN 1 AND 20
GROUP BY COUNT
ORDER BY last_name DESC, first_name ASC, actor_id DESC
LIMIT 5;
-- same as
SELECT first_name, last_name, actor_id
FROM ACTOR
WHERE actor_id BETWEEN 1 AND 20
ORDER BY 2 DESC, 1 ASC, 3 DESC;
An example using all the above statements is shown below
SELECT last_name, COUNT(ALL last_name) AS COUNT_NAME
FROM ACTOR
GROUP BY last_name
HAVING COUNT_NAME>1
ORDER BY COUNT_NAME DESC, last_name DESC;
SQL server specific functions
All SQL implementations offer functions which makes it incredibly easy to perform some common operations. However, not all of these functions below are available in all implementations, and hence we will note when they are not available in MySQL.
Note: MySQL will throw an error if there is space between function name and parentheses.
String and character functions
Note: the index in SQL functions (such as SUBSTRING() start from 1).
CONCAT('string1, 'string2', ...)TRANSLATE(string, from_string, to_string)Not available in MySQLREPLACE(original_string_containing_col, from_string, to_string)replaces the original string which contains from_substring with to_string.UPPERLOWERSUBSTRING (column_name, starting_position, length)(synonymSUBSTR)LTRIMRTRIMLENGTHIFNULLonly available in MySQLCOALESCELPADRPAD
Mathematics functions
ROUND(col_name, round_digits)Used to round up a decimal valueFLOOR()round down to the nearest integer conversion functions
CASE functions (similar to IF-else statements)
Example to figure out whether a given triangle is equilateral, isoceles or scalene:
SELECT
CASE
WHEN A + B <= C OR B + C <= A OR A + C <= B THEN "Not A Triangle"
WHEN A = B AND B = C THEN "Equilateral"
WHEN A = B OR B = C OR A = C AND (A + B >= C OR B + C >= A OR A + C >= B) THEN "Isosceles"
-- WHEN A != B AND B != C THEN "Scalene"
ELSE "Scalene"
END
FROM TRIANGLES;
Datetime functions
-SELECT NOW (); picking today’s date
JOINS
Most common type is known as equijoin or an inner join.
-- example of equijoin from sakila
SELECT P.amount, C.last_name, C.customer_id
FROM payment AS P, customer AS C
WHERE P.customer_id = C.customer_id AND p.amount > 10;
-- this is more like a join syntax
SELECT P.amount, C.last_name, C.customer_id
FROM payment AS P INNER JOIN customer AS C
ON P.customer_id = C.customer_id
WHERE p.amount>10;
SELECT *
FROM rental;
SELECT *
FROM inventory;
SELECT R.rental_id, R.inventory_id,I.store_id, I.film_id, F.title
FROM rental R INNER JOIN inventory I INNER JOIN film F
ON R.inventory_id = I.inventory_id AND I.film_id = F.film_id
LIMIT 100000;
Combining queries
Queries can be combined by:
UNIONandUNION ALLINTERSECTEXCEPT