Web scraping Google chrome web store extension user reviews
Introduction
Let us analyze reviews data from a very popular restaurant in Atlanta, GA called Antico Pizza.
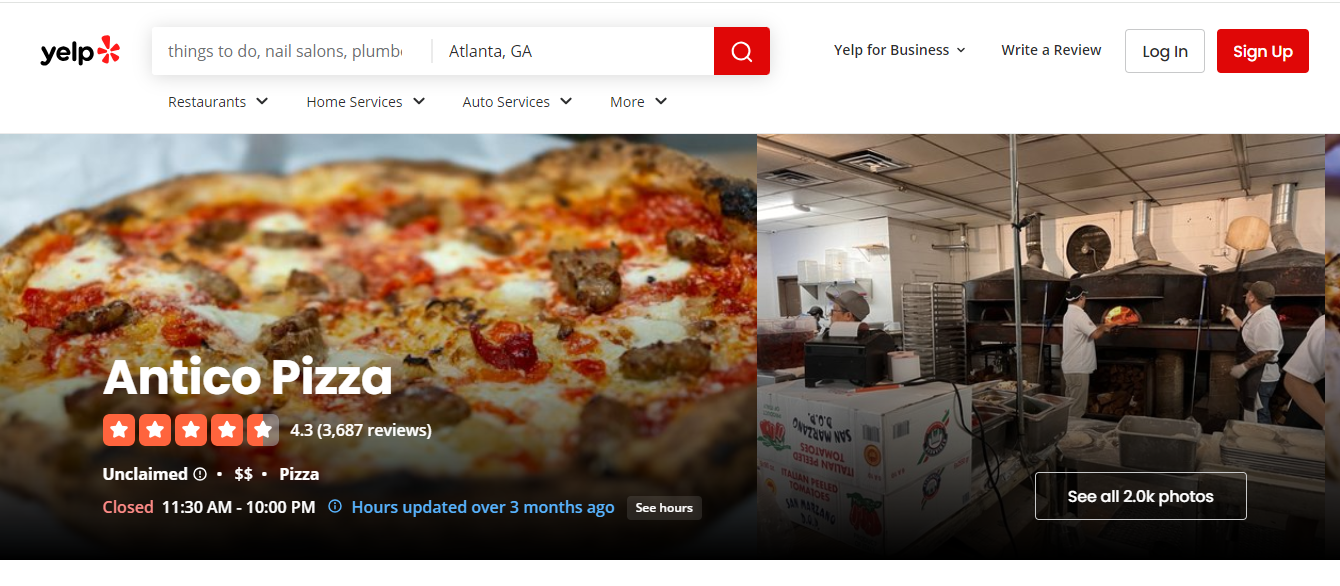
It is super popular restaurant with over 3600 reviews with an average rating of 4.3.
First impressions
Yelp rating algorithm flags certain percentage of reviews for being fake, unhelpful, or biased or just unsuitable for overall Yelp audience. It labels them as “non recommended”. These reviews are still visible after couple of extra clicks.
Businesses can report certain reviews that they believe to go against the Yelp’s guidelines and these reviews will get removed.
This business has 689 not recommended reviews and 66 removed reviews.
Yelp has publicly mentioned that their algorithm on an average filters out about 25% reviews as “not recommended”. Here the number comes out to roughly 19% so its very much within the ballpark.
As far as review removal goes, 66 is also a decent number for a restaurant within Southeast US.
In the aftermath of the covid-19 pandemic, lots of restaurants responded by making masking mandatory for customers. In some parts of US, this resulted in a flood of bad reviews by customers that didn’t like masking or taking other covid precautions.
In light of that, yelp came out with updated covid 19 content guidelines that basically allowed businesses to report and remove reviews that were solely Criticizing covid-19 precautions, masking etc.
So lots of reviews got removed during 2020-2022 for simply that reason, and for this business 66 removed reviews are pretty low end of that and doesnt represent large scale rigging of reviews.
Number of reviews per year
We wanted to get a snapshot of how the business was doing in past few years. Hence we scraped 600 recent reviews.
Let us look at reviews per year trends.
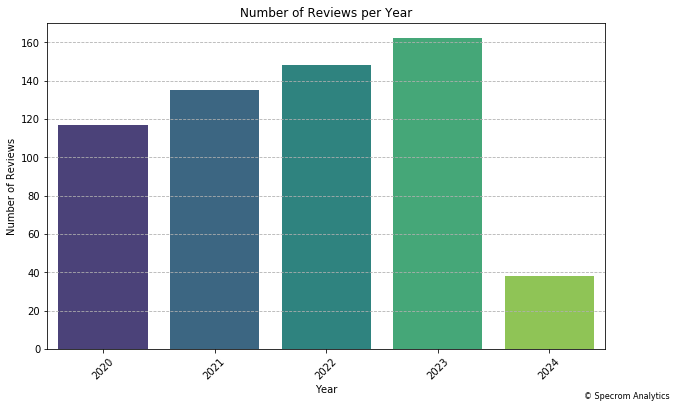
The data reflects the annual review trends from 2020 through the first four months of 2024. Starting in 2020, with the onset of the COVID-19 pandemic, there were 117 reviews.
As the world began to adapt to the pandemic conditions in 2021, the number of reviews increased to 155, suggesting a rebound in activity. This rise could be attributed to greater adaptation to delivery only business which should be robust for a Pizza restaurant like this one compared to restaurants that offered other cuisines
The upward trend continued into 2022 and 2023, with the numbers growing to 185 and 193 reviews, respectively. This consistent increase might reflect a sustained recovery and growth phase as the initial impacts of the pandemic lessened and normalcy began to resume in many areas of life.
However, in 2024, the data shows only 50 reviews for the first four months. This apparent decline should not be immediately interpreted as a downturn but rather seen in the context of the data only covering a partial year. Extrapolating this number could suggest that the review count might align closely with previous years if the trend continues similarly throughout the remainder of the year.
Let us also take a look at number of reviews for 1, 2 3, 4 and 5 star rating.
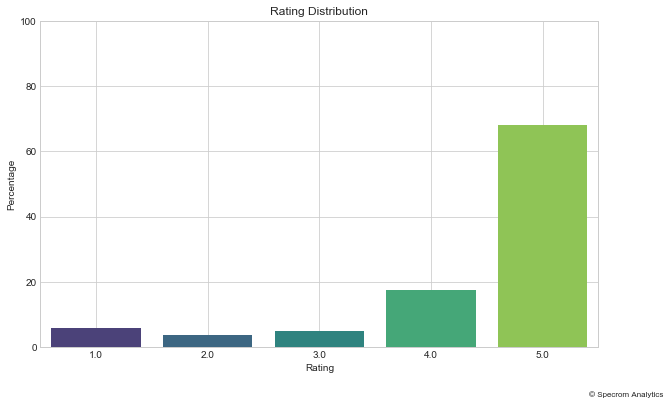
Average rating using recent reviews
We already explained in introduction that Yelp algorithm assigns a rating value after excluding a certain number of reviews as “not recommended”.
A yelp rating value also represents aggregate for a business over its entire business duration.
So a business that’s been operating for past 15 years might still have a high rating value even though in past few years the quality of services or food may have gone downhill (with a flood of bad reviews).
Hence, we calculate an average rating per year using recent reviews only and lets see how that value changes in past few years.
In this plot, we have taken an average of all the review ratings for a given year. We than plot that against year as X axis. So we see how ratings vary per year.
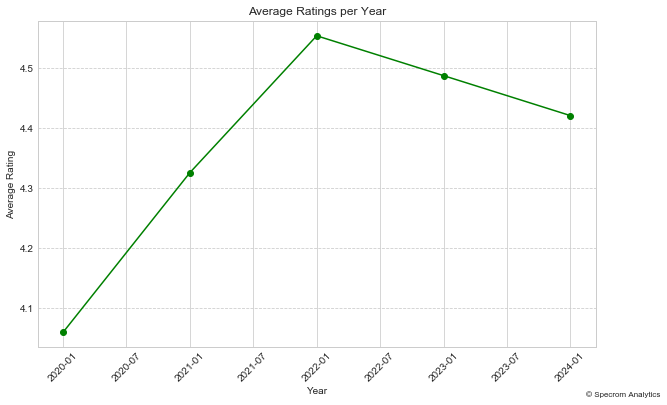
As you can see it goes up from 4 to over 4.3 in past few years. This essentially shows that the restaurant continues to offer high quality food and services and when we only take into account the recent reviews, the average rating is a bit higher than the aggregate yelp rating.
To get a more in depth look at how cumulative reviews till date changed the total rating score, take a look below.
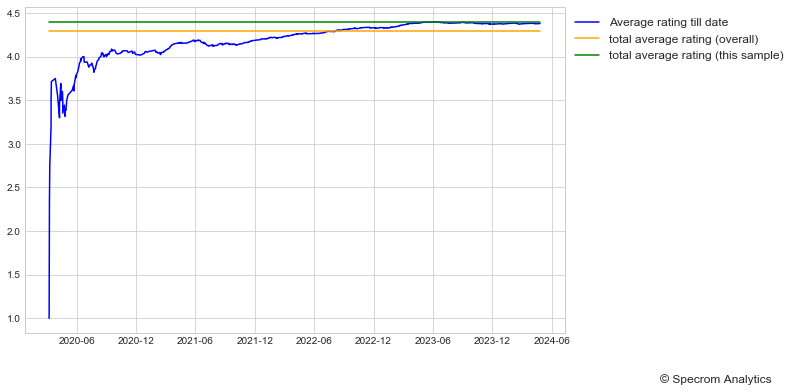
This plot is slightly different than above. In this case we calculate something called average rating till date. Essentially, it takes individual review ratings of all the published reviews till that date and averages it.
So as time goes by, you can see incremental effect of a new review on the total average rating. This lets you visualize the roughly the time periods that contain lots of negative reviews and how the overall trend was affected by it.
Sentiments analysis using recent reviews
So firstly, lets label 1-2 star reviews as negative, three star reviews as neutral, 4 and 5 star one as positive.
For this simplistic analysis, we are going to ignore the review text itself.
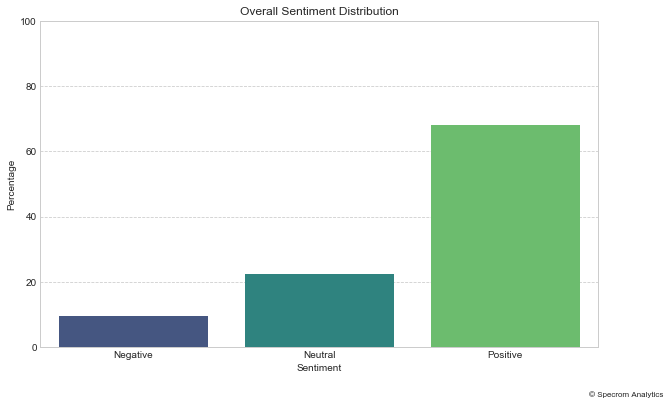
Now, lets ignore the review star rating, and just run a sentiments AL model on the review text.
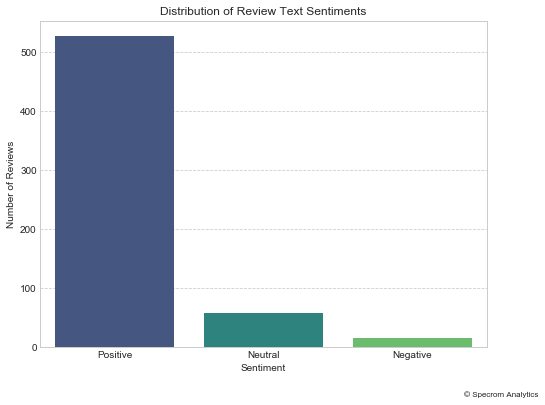
In this case, we see that the review text itself is more positive than what the review rating might otherwise indicate. This is quite common though, lots of people will offer 2-3 star reviews but the text itself is more balanced. Another common issue is that people will post negative reviews but dont explain why they didnt like it.
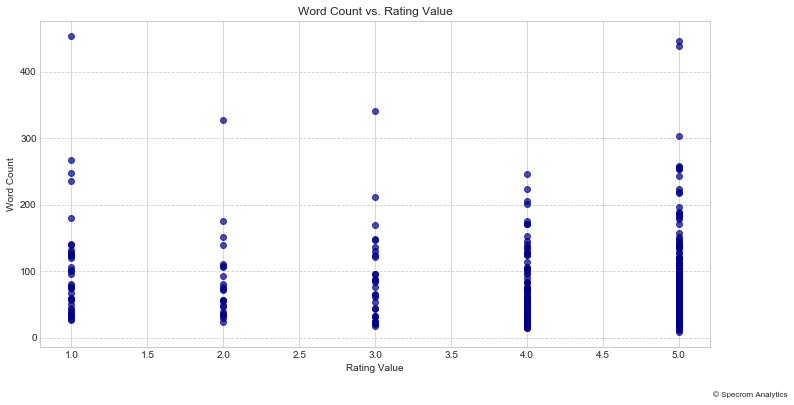
To capture such instances, let us plot word counts of each reviews versus the rating value of the review itself.
wordcloud
Lets visualize the most common words mentioned in the reviews.
yelp_wordcloud.png
Its no surprise that most common words are Pizza, Atlanta, etc.
Aspect based sentiments
The wordclouds are by themselves not too useful. To glean more detailed insights from it, we can extract out the most common “aspects” or “topics” that reviewers mentioned in their text, and based on the context of the review text, we can assign sentiments to it.
So basically if someone mentioned that the service was slow; we would take the aspect (service in this case) and assign it a negative score.
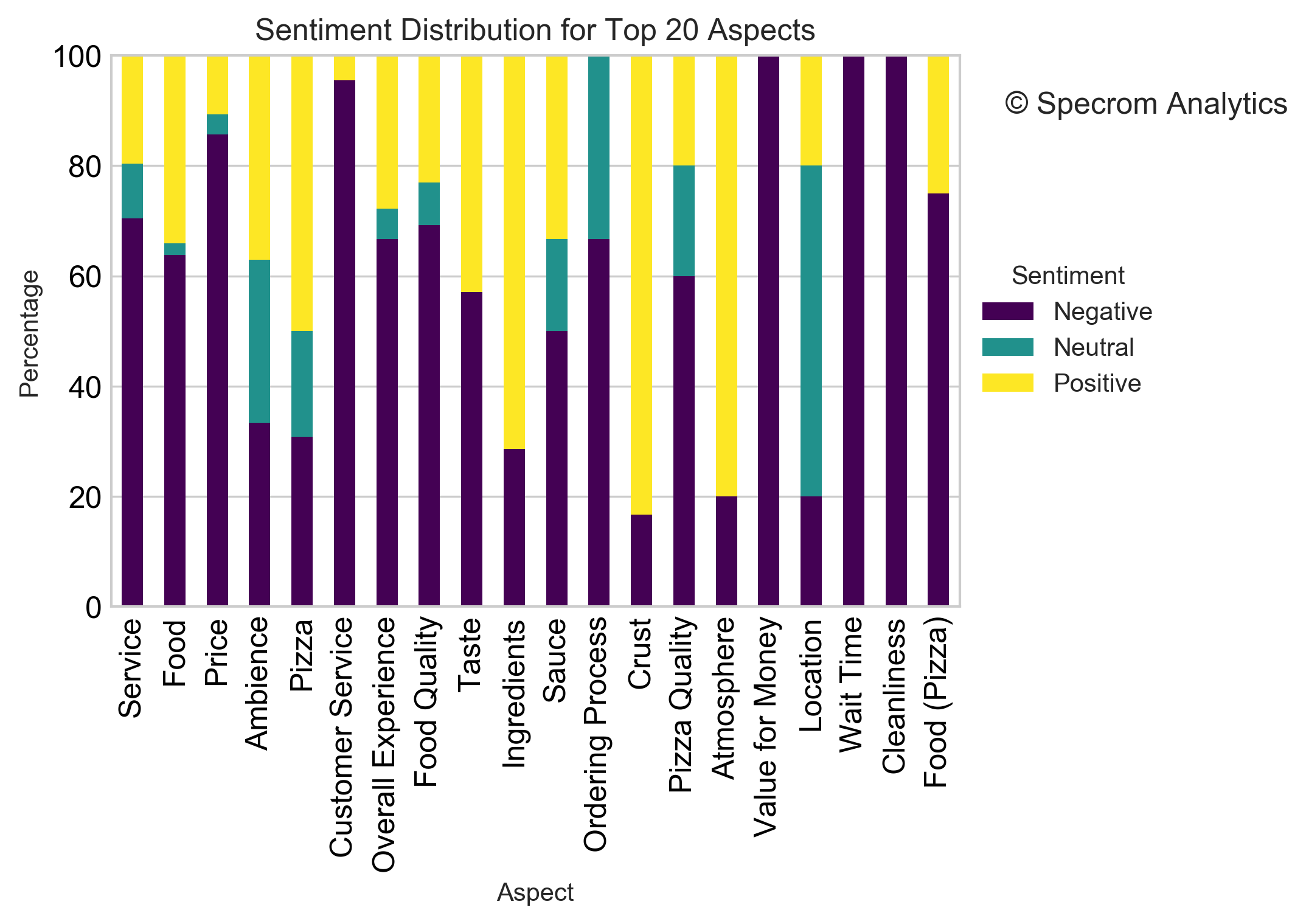
We have to put things in right context; reviewers are happy and write about vareity of things that led to their positive experience; however, there are handful of similar aspects that leds them to write a negative review or say a negative thing.
For a restaurant, presumably this will be related to service & food and value for money.
The bright spot was that more reviewers left a positive review for pizza and ingredients.
It was almost all negative reviews for value for money, waittimes so that is something the business should carefully look at.
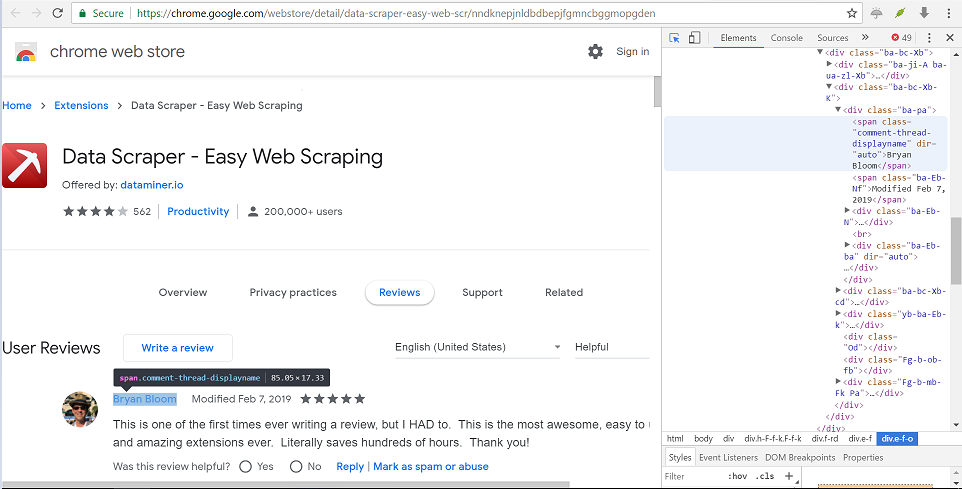
Figure 1: Screenshot of Google chrome web store extension reviews.
At the end of this article, you will be able to extract these individual elements highlighted in red in figure 2.

Figure 2: Screenshot of important elements to extract from individual Google chrome web store user review.
Option 1: Hire a fully managed web scraping service.
You can contact us contact us for our fully managed web scraping service to get chrome web store extension reviews data as a CSV or excel file without dealing with any coding.
Our pricing starts at $99 for fully managed Google chrome web store scraping.
You can simply sit back and just give us a list of chrome extension urls or ids and let us handle all complexities of web scraping a site like Google that has plenty of anti-scraping protections built in to try and dissuade from people scraping it in bulk.
We can also create a rest API endpoint for you if you want structured data on demand.
Option 2: Scrape Google chrome web store extension reviews on your own
We will use a browser automation library called Selenium to extract results for the a particular extension in chrome web store.
Selenium has bindings available in all major programming language so you use whichever language you like, but we will use Python here.
# Using Selenium to extract Chrome web store reviews
from selenium import webdriver
import time
from bs4 import BeautifulSoup
test_url = 'https://chrome.google.com/webstore/detail/data-scraper-easy-web-scr/nndknepjnldbdbepjfgmncbggmopgden'
option = webdriver.ChromeOptions()
option.add_argument("--incognito")
chromedriver = r'chromedriver.exe'
browser = webdriver.Chrome(chromedriver, options=option)
browser.get(test_url)
html_source = browser.page_source
Parsing individual fields
Let us parse basic information such as extension name, total users, and aggregate rating value.
Extracting basic information about the extension
# extracting chrome extension name
soup=BeautifulSoup(html_source, "html.parser")
print(soup.find_all('h1',{'class','e-f-w'})[0].get_text())
total_users = soup.find_all('span',{'class','e-f-ih'})[0].get_text()
print(total_users.strip())
total_reviews = soup.find_all('div',{'class','nAtiRe'})[0].get_text()
print(total_reviews.strip())
# rating value
meta=soup.find_all('meta')
for val in meta:
try:
if val['itemprop']=='ratingValue':
print(val['content'])
except:
pass
#Output
'Data Scraper - Easy Web Scraping'
'200,000+ users'
'562'
4.080071174377224
Once we have the basic information, we will click on the reviews tab programmatically so that we can load all the reviews and scroll till the end of the page.
# clicking reviews button
element = browser.find_element_by_xpath('//*[@id=":25"]/div/div')
element.click()
time.sleep(5)
# scrolling till end of the page
from selenium.webdriver.common.keys import Keys
html = browser.find_element_by_tag_name('html')
html.send_keys(Keys.END)
html_source = browser.page_source
browser.close()
soup=BeautifulSoup(html_source, 'html.parser')
Extracting review author names
Let’s extract review author names.
review_author_list_src = soup.find_all('span', {'class','comment-thread-displayname'})
review_author_name_list = []
for val in review_author_list_src:
try:
review_author_name_list.append(val.get_text())
except:
pass
review_author_name_list[:10]
#Output
['Bryan Bloom',
'Sudhakar Kadavasal',
'Lauren Rich',
'�yvind Andr� Sandberg',
'Paul Adamson',
'Phoebe Staab',
'Frank Mathmann',
'Bobby Thomas',
'Kevin Humphrey',
'David Wills']
Extracting review date
The next step is extracting review dates of each review.
# extracting review dates
date_src = soup.find_all('span',{'class', 'ba-Eb-Nf'})
date_src
date_list = []
for val in date_src:
date_list.append(val.get_text())
date_list[:10]
# Output
['Modified Feb 7, 2019',
'Modified Jan 8, 2019',
'Modified Dec 31, 2018',
'Modified Jan 4, 2019',
'Modified Dec 14, 2018',
'Modified Feb 5, 2019',
'Modified Dec 13, 2018',
'Modified Jan 16, 2019',
'Modified Nov 29, 2018',
'Modified Nov 16, 2018']
Extracting review star rating
You can perform sentiments analysis on review contents, but its generally a good idea to use the star rating of the review itself for a weighted average on the sentiments, if the sentiments fall in neutral area, or alternately, just use the star rating for calibration of your text sentiments analysis model itself if you are in model development.
# extracting review star rating
star_rating_src = soup.find_all('div', {'class','rsw-stars'})
star_rating_list = []
for val in star_rating_src:
try:
star_rating_list.append(val['aria-label'])
except:
pass
star_rating_list[:10]
# Output
['5 stars',
'5 stars',
'5 stars',
'5 stars',
'5 stars',
'5 stars',
'5 stars',
'2 stars',
'5 stars',
'5 stars']
Extracting review contents
For brevity we will only show results from first three results, and you can verify that the first result matches the text in figure 2 above.
# extracting review content
review_content_src = soup.find_all('div',{'class', 'ba-Eb-ba'})
review_content_list = []
for val in review_content_src:
review_content_list.append(val.get_text())
review_content_list[:3]
# Output
['This is one of the first times ever writing a review, but I HAD to. This is the most awesome, easy to use and amazing extensions ever. Literally saves hundreds of hours. Thank you!',
'Loved it. It automatically detected the data structure suited for the website and that helped me in learning how to use the tool without having to read the tutorial! Beautifully written tool. Kudos.',
'Great tool for mining data. We used Data Miner to extract data from the Medicare.gov website for an upcoming mailing to nursing homes and assisted living facilities. It can comb through a number of pages in a matter of seconds, extracting thousands of rows into one concise spreadsheet. I would highly recommend this product to any business looking to obtain data for any purpose - mailing, email campaign, etc. Thank you Data Miner!']
Converting into CSV file
You can take the lists above, and read it as a pandas DataFrame. Once you have the Dataframe, you can convert to CSV, Excel or JSON easily without any issues.
Scaling up to a full crawler for extracting all google chrome web store reviews of an app
Pagination
- To fetch all the reviews, you will have to paginate through the results.
Implementing anti-CAPTCHA measures
After few dozen requests, the Google.com servers will start blocking your IP address outright or you will be flagged and will start getting CAPTCHA.
For successfully fetching data, you will have to implement:
- rotating proxy IP addresses preferably using residential proxies.
- rotate user agents
- Use an external CAPTCHA solving service like 2captcha or anticaptcha.com
After you follow all the steps above, you will realize that our pricing for managed web scraping is one of the most competitive in the market.