Scraping Dillard's Stores Location
So, what is the easiest way to get CSV file of all the Dillard’s store locations data in the USA?
Buy the Dillard’s store data from our data store
There are Dillard’s stores acorss USA and you buy the CSV file containing address, city, zip, latitude, longitude of each location in our data store for $50.
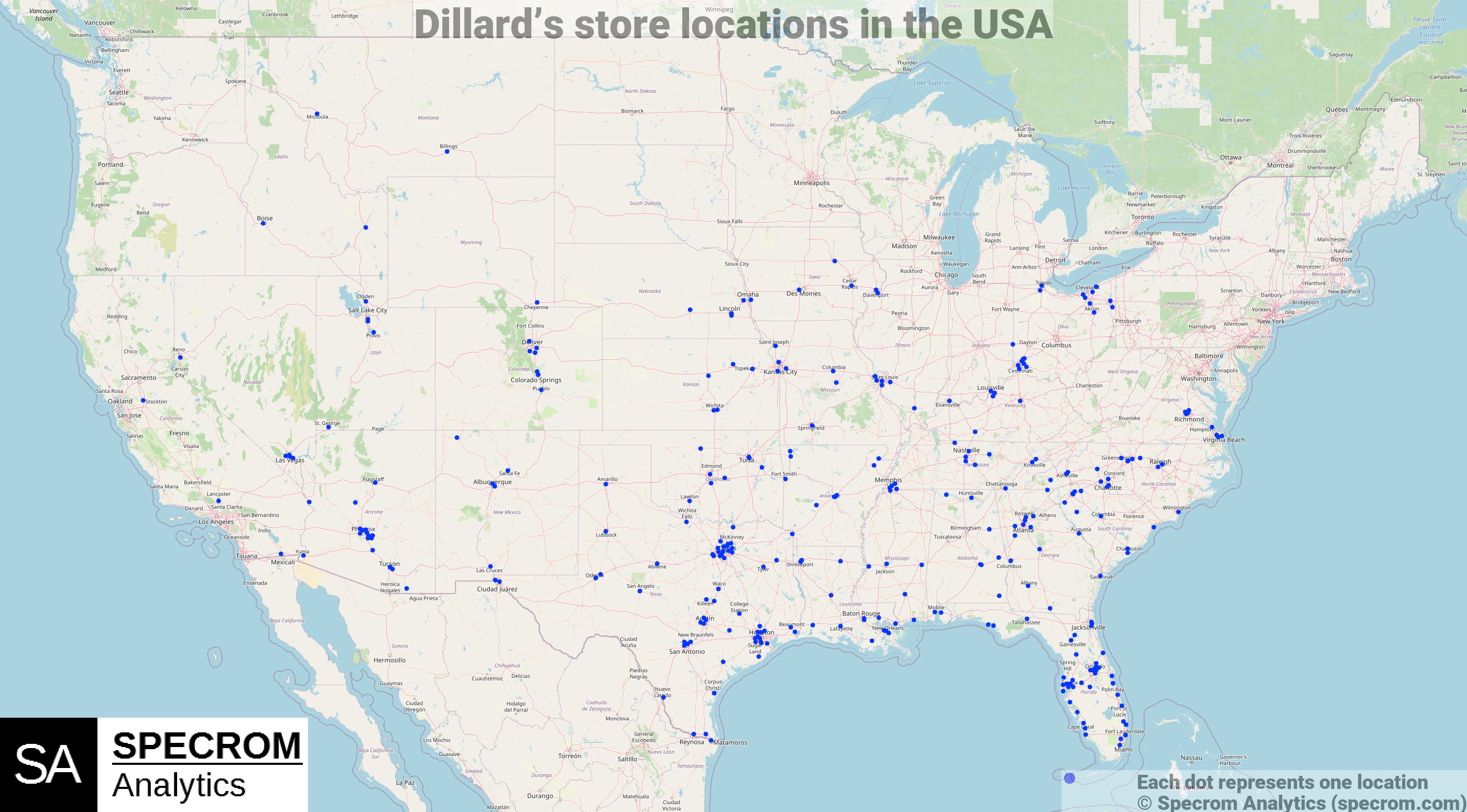
Figure 1: Dillard’s store locations. Source: Dillard’s Store Locations dataset
If you are instead interested in scraping for locations on your own than continue reading rest of the article.
Scraping Dillard’s stores locator webpage using Python
Python is great for web scraping and we will be using a library called Selenium to extract Dillard’s store locator’s raw html source.
- Fetching raw html page from the Dillard’s store locator page.
### Using Selenium to extract Dillard's store locator's raw html source
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
test_url = 'https://www.dillards.com/stores'
option = webdriver.ChromeOptions()
option.add_argument("--incognito")
chromedriver = r'chromedriver_path'
browser = webdriver.Chrome(chromedriver, options=option)
browser.get(test_url)
html_source = browser.page_source
browser.close()
Using BeautifulSoup to extract Dillard’s store details
Once we have the raw html source, we should use a Python library called BeautifulSoup for parsing the raw html files.
- You should open the page in the chrome browser and click inspect.
Figure 2: Inspecting the source of Dillards store locator.
- We will extract store names.
# extracting Dillard's store names
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_source, "html.parser")
store_name_list_src = soup.find_all('div', {'class','col-sm-12 col-md-3'})
store_name_list = []
for val in store_name_list_src:
try:
store_name_list.append(val.get_text())
except:
pass
store_name_list[:10]
#Output
['Auburn',
'Auburn Mall',
'Dothan',
'Wiregrass Commons Mall',
'Florence',
'Regency Square Mall',
'Huntsville',
'Parkway Place',
'Mobile',
'The Shoppes At Bel Air']
The next step is extracting addresses. Referring back to the inspect in the chrome browser, we see that each address text is in fact of the class name col-sm-12 col-md-3 underline so we just use the BeautifulSoup find_all method to extract that into a list.
- The data will still require some cleaning to extract out address line 1,address line 2, city, state, zipcode and phone numbers but thats just basic Python string manipulation and we will leave that as an exercise to the reader.
# extracting Dillards addresses
addresses_src = soup.find_all('div',{'class', 'col-sm-12 col-md-3 underline'})
addresses_src
address_list = []
for val in addresses_src:
address_list.append(val.get_text())
address_list[:10]
# Output
[
'(334) 821-3900',
'1627 Opelika Rd #16Auburn, AL 36830',
'(334) 794-3300',
'900 Commons Dr #100Dothan, AL 36303',
'(256) 766-8200',
'301 Cox Creek Pkwy Ste #1100Florence, AL 35630',
'(256) 551-0179',
'2801 Memorial Pkwy SWHuntsville, AL 35801',
'(251) 471-1551',
'3300 Joe Treadwell DrMobile, AL 36606']
Each local store location has its own URL where additional information such as store closing times, phone numbers etc. is available.
# extracting store urls
store_url_list = []
for val in store_name_list_src:
try:
store_url_list.append('https://www.dillards.com/stores/'+val.find('a')['href'])
except:
pass
store_url_list[:10]
#Output
['https://www.dillards.com/stores//stores/auburn-mall-auburn-alabama/0417',
'https://www.dillards.com/stores//stores/wiregrass-commons-mall-dothan-alabama/0274',
'https://www.dillards.com/stores//stores/regency-square-mall-florence-alabama/0453',
'https://www.dillards.com/stores//stores/parkway-place-huntsville-alabama/0460',
'https://www.dillards.com/stores//stores/the-shoppes-at-bel-air-mobile-alabama/0241',
'https://www.dillards.com/stores//stores/eastdale-mall-montgomery-alabama/0514',
'https://www.dillards.com/stores//stores/the-shoppes-at-eastchase-montgomery-alabama/0418',
'https://www.dillards.com/stores//stores/quintard-mall-oxford-alabama/0416',
'https://www.dillards.com/stores//stores/eastern-shore-centre-spanish-fort-alabama/0239',
'https://www.dillards.com/stores//stores/promenade-at-casa-grande-casa-grande-arizona/0505']
Web scraping at scale for getting all Dillard’s store locations
Dillards.com servers will try to block your IP address outright or you will be flagged and will start getting CAPTCHA once you try to fetch too much data programmatically.
- To make it more likely to successfully fetch data for all USA, you will have to implement:
- rotating proxy IP addresses preferably using residential proxies.
- rotate user agents
- Use an external CAPTCHA solving service like 2captcha or anticaptcha.com
After you follow all the steps above, you will realize that our pricing($50) for web scraped store locations data for all Dillards stores location is one of the most competitive in the market.